This is the FpML 4.0 Working Draft #2 for review by the public and by FpML members and working groups. It is a draft document
and may be updated, replaced or obsoleted by other documents at any time. It is inappropriate to use FpML Working Drafts
as reference material or to cite them as other than "work in progress". This is work in progress and does not imply endorsement
by ISDA.
The FpML Working Groups encourage reviewing organizations to provide feedback as early as possible. Comments on this document
should be sent by filling in the form at the following link: http://www.fpml.org/issues. An archive of the comments is available at http://www.fpml.org/issues/archive.asp
Public discussion of FpML takes place on the FpML Discussion List: discuss@fpml.org which you can join at the following link:
While implementation experience reports are welcomed, the FpML Standards Committee will not allow early implementation to
constrain its ability to make changes to this specification prior to final release.
This document has been produced as part of the FpML 4.0 activity and is part of the Standards Approval Process.
The Financial Products Markup Language (FpML) is a protocol enabling e-commerce activities in the field of financial derivatives.
The development of the standard, controlled by ISDA (the International Swaps and Derivatives Association), will ultimately
allow the electronic integration of a range of services, from electronic trading and confirmations to portfolio specification
for risk analysis. All types of over-the-counter (OTC) derivatives will, over time, be incorporated into the standard. FpML
4.0 covers FX and Interest Rate, Equity, and Credit Derivatives.
FpML is an application of XML, an internet standard language for describing data shared between computer applications.
Following is a brief list of the changes to be found in this working draft compared to working draft #1.
Many "schemes" have been replaced by enumerations, in cases where the domain was judged to be relatively stable. In addition,
all scheme default attributes have been removed from the FpML root element. Schemes that have been converted to enumerations
no longer require a scheme default. Other schemes are now defaulted, where possible, as default attribute values in the schema.
This change was made to improve the maintainability and readability of the FpML root element, and to make it clearer when
non-default schemes are used.
Most global element definitions have been turned into local element definitions. This change was made to reduce cross-asset
name clashes and improve flexibility going forward. It also had the side benefit of reducing the documentation size by approximately
400-500 pages. This change has significantly changed the schema files, but not changed the instance documents.
There have been a few smalll changes to Credit Derivative definitions (e.g. addition of new scheme values) to address the
ISDA 2003 credit derivatives supplement.
Enhancements to IRD cashflows recently incorporated into versions 2.0 and 3.0 have also been included in version 4.0.
There have been a few changes to message headers and reject messages to address recommendations by the Validation working
group.
Most diagrams have been redone to improve quality.
Example files have been renamed for clarity and consistency
Following is a brief list of the changes to be found in this document compared to FpML 3.0.
Use of XML Schema. FpML 4.0 is the first FpML version to use XML Schema as the normative definition; this has affected the
organization and contents of the type definitions section.
New Equity Derivative products, including exotic options and equity swaps.
New Credit Derivative products, specifically Credit Default Swaps.
New Term Deposit product, in the FX section.
Message Headers. A first version of an FpML messaging framework has been incorporated.
Document production process. There have been some changes to the document production process.
FpML type definitions are now expressed using XML Schema. This replaces the document type reference (DOCTYPE directive) in
each FpML document with new attributes for specifying namespaces and schema locations on the "FpML" root element. In addition
the correct document content model must be selected by setting the type of the root element. The main body of the document
is unaffected by the transistion to XML schema.
With the conversion of many schemes to enumerations, we have chosen to eliminate all scheme defaults from the FpML root element
and replace them in some cases with default attribute values in the schema. To convert instance documents from version 3.0,
you will need to remove scheme default attributes from the root element. In cases where a scheme has been converted to an
enumeration, it will no longer be possible to use a proprietary set of domain values.
Intra-document references (using the "href" attribute) now no longer have a "#" prefix, due to the change to id/idref semantics
from the xlink referencing style. This change is also planned to be made to FpML 3.0, but is incompatible with instance documents
developed to date. To change instance documents to accommodate the change it will be necessary to remove the "#" prefix from
href attribute values.
In FpML 3.0 an entry was added to the trade header to specify a calculation agent. With FpML 4.0 this has been rationalized
with an entry in the trade element which specifies the calculation agent(s). Documents using the calculationAgentReference
in the tradeHeader will need to be changed to use the calculationAgent element in the "trade" element.
The masterConfirmation element now appears before the contractualDefinitions element in the definition of the Documentation
type. Furthermore, in FpML 4.0 the masterConfirmation element is no longer simply a date. In 4.0 it consists of a masterConfirmationType,
masterConfirmationDate and an optional masterConfirmationAnnexDate.
All FpML 3.0 documents that contain a masterConfirmation element are incompatible with FpML 4.0. Do the following in order
to upgrade your 3.0 documents to 4.0:
If the document contains both a masterConfirmation and a contractualDefinitions element(s), reverse the order of these elements.
Move the date value that appears in the masterConfirmation element to the element masterConfirmation.masterConfirmationDate.
Add the element masterConfirmation.masterConfirmationType with the appropriate value.
Messages constructed using FpML 4.0 should make use of the new message framework to express the reason for the exchange of
information, to identify the parties involved in the exchange and to describe the actual information itself.
A number of standard messages have been provided for trade affirmation and confirmation along with error reporting and trade
status enquiry. FpML users can derive additional message types from the framework to meet specific messaging requirements
currently outside FpML's scope.
To allow backwards compatibility with existing pre-FpML 4.0 documents a 'DataDocument' type has been provided which does not
include message elements.
Following is a list of changes that are anticipated to be made by the time the document reaches Last Call Working Draft:
A number of definitions that are used in several places in the document are likely to be moved to the "shared" subschema.
In a number of places where the localization of global elements has created repeated definitions of the same basic type, we
plan to create global types. Examples include intra-document references such as party references, invocations of schemes,
etc.
A number of global types are likely to be renamed to improve clarity of scope/purpose.
We will attempt to rationalize/consolidate a number of definitions across asset classes.
There have been several comments proposing localized enhancements, to areas including the tradeHeader and the party element,
that are likely to be addressed.
The scope of FpML 4.0 includes all of the FpML 3.0 scope plus significantly broadened Equity Derivative product coverage,
new Credit Derivative product coverage, and support for an FpML Messaging framework.
The various Working Groups have developed FpML 4.0 within an architecture framework updated from the FpML Architecture Version
1.0 framework defined by the Architecture Working Group. The original FpML 1.0 Architecture framework recommendations covered:
XML tools for editing and parsing
XML namespace usage within FpML
FpML versioning methodology
FpML content model - a new style for representing the FpML Document Type Definition (DTD)
FpML referencing methodology, including guidelines for referencing coding schemes.
The principal changes from the original FpML 1.0 architecture framework include:
Replacement of XML DTDs (Document Type Definitions) by XML Schemas, as described in a technical note published in 2002 by
the FpML Architecture WG.
Elimination of xlink-style referencing and its replacment with id/idref-style referencing (this change is also being adopted
for FpML 3.0).
The Architecture Working Group intends to publish a new architecture framework incorporating the above changes, and some others,
including, among other topics:
Proprietary extensions to FpML
Enhanced versioning support
Digital signature support
This updated architecture framework is likely to be published as separate document during the working draft stage of FpML
4.0.
We have included support for various types of Equity Swaps, without any specific limitation. Those identified so far include:
Single stock swaps as well as basket swaps
Swaps that have an equity, index or a convertible bond underlyers, or a combination of these
2-legged swaps with a combination of an equity leg and a funding leg, as well as swaps that either have only one leg (e.g.
fully funded swap) or multiple equity legs
Trigger swaps, which equity return is replaced by a fixed income return once certain market conditions are met
Swaps that have specific adjustment conditions, such as execution swaps or portfolio rebalancing swaps
Zero-strike swaps, which do not have an interest rate component but rather involve the exchange of principal cashflows
The FpML representation of the equity swap is focused on representing the economic
description of the swap. The expectation is that the reference terms of the swap will
be defined either through the ISDA definitions or, when exceptions apply, through
master bilateral agreements that will be agreed between the parties to the trade
In order to support the above scope for both Equity Derivative and Equity Swap products we support operational features, such
as contact information and governing documentation which are present in current documents defined by ISDA standards
An FpML messaging working group has been formed to define a messaging framework and sample messages for selected business
processes. FpML 4.0 Working Draft #2 includes a preliminary version of this working group's output; it is expected to evolve
somewhat in future drafts of FpML 4.0. Business processes currently addressed by this Working Group include:
Trade Affirmation
Trade Confirmation
To support these business processes, a number of messages have been defined. Please see the "Message Architecture" section
for more informtion.
In FpML 4.0 Working Draft #2 no Energy Derivative products are covered. However, a working group is currently active in this
area and is expected to provide support for the following products in the next version of FpML:
Financial Gas swaps, caps/floors, and swaptions
Financial Power swaps, caps/floors, and swaptions
Financial Oil swaps, caps/floors, and swaptions
It is anticipated that support for physically-settled products will be incorporated in future versions of FpML.
An FpML validation working group began in February 2003. This draft incorporates some initial results from that working group,
in the message header and reject message.
FpML incorporates a significant level of structure, rather than being a 'flat' representation of data. This structuring is
achieved through the grouping of related elements describing particular features of a trade into components. Components can
both contain, and be contained by, other components.
An alternative approach would have been to collect all the required elements in a single large component representing a product
or trade. A flat structure of this kind would capture all the relevant information concisely but would also constrain the
model in two important respects, namely, ease of implementation and extensibility.
Grouping related elements into components makes it easier to validate that the model is correct, that it is complete and that
it doesn't contain redundancy. This is true, both from the perspective of readability to the human eye, and also from the
perspective of processing services. Processing services that do not need all the information in a trade definition can isolate
components and be sure that the complete set of elements required, and only the elements required, is available for the particular
process in hand.
Components additionally serve as the building blocks for a flexible and extensible model. Generally speaking, the complexity
of financial products is a result of combining a few simple ideas in a variety of different ways. The component structure
supports a trade content definition that is flexible enough to represent the wide variation of features found in traded financial
instruments.
It should be noted that the application of the guiding principles of extensibility and ease of use has resulted in a different
approach with regard to the forward rate agreement. Because this product is straightforward, commoditized and unlikely to
develop further, the advantage to be gained from the extensive use of components is outweighed by the concision of a single
component.
The optimum level of granularity is important to FpML. FpML separates the elements which collectively describe a feature
of a product or trade into a separate component with each component serving a particular semantic purpose. Every grouping
of elements in FpML is regarded as a component and each component is regarded as a container for the elements that describe
that component. In the majority of cases each component will contain a mixture of other components and primitive elements,
e.g. a date or string, that collectively describe the features of the component. Components are typically represented in
the FpML schema as Complex Types.
Generally speaking, the lower level a component is, the more re-usable it will be. FpML makes use of a number of primitive
entity components that describe the basic building blocks of financial products, for example, FpML_Money, FpML_AdjustableDate,
FpML_BusinessCenters, FpML_Interval, FpML_BusinessDayAdjustments etc. These primitive components are re-used in different
business contexts.
Primitive components are contained in higher level components that describe the features of particular products. For this
reason these higher level components will tend not to be re-usable to the same extent. Examples within the definition of swapStream
are the components required to construct schedules of dates such as calculationPeriodDates, resetDates and paymentDates.
However, it should not be inferred from this that any fundamental distinction is drawn between components in usage or structure.
The root element contains three elements, trades, portfolios and parties. Portfolios contain only trade references, if the
trades themselves need to be included in the document then the trades can be included within the root element.
The FpML element forms the root for an FpML instance document. The structure of the FpML document depends on the "type" attribute,
which is a subtype of "Message". The simplest FpML document is a "DataDocument", which is similar to an FpML 3.0 document.
A DataDocument looks like this:
It contains:
A trade or trades
A portfolio or portfolios
A party or parties
In addition, the FpML root element includes attributes for:
Specifying the FpML version and related schemas and namespaces.
Each FpML document contains a message header, which provides a context for the document. The header includes information
about the sender and recipient of the message and the purpose of the message. See the section on "Messaging Architecture"
for more information.
The trade is the top-level component within the root element FpML. A trade is an agreement between two parties to enter into
a financial contract and the trade component in FpML contains the information necessary to execute and confirm that trade.
The information within tradeHeader is common across all types of trade regardless of product. In FpML 4.0 this element contains
the trade date and party trade identifiers.
The portfolio component specifies a set of trades as a list of tradeIds and a list of sub portfolios. Portfolios can be composed
of other portfolios using a composition pattern. By using the tradeId to identify the trade the standard allows for portfolios
to be sent around without the full trade record.
The party component holds information about a party in involved any of the trades or portfolios included in the document.
The parties involved will be the principals to a trade and potentially additional third parties such as a broker. For this
release, this component is restricted to party identification.
It should be noted that an FpML document is not 'written' from the perspective of one particular party, i.e. it is symmetrical
with respect to the principal parties. The particular role that a party plays in the trade, e.g. buyer, seller, stream payer/receiver,
fee payer/receiver, is modeled via the use of references from the component where the role is identified to the party component.
The product component specifies the financial instrument being traded. This component captures the economic details of the
trade. It is modeled as a substitution group; each asset class may create one or more product definitions. Some examples
of products that different working groups have defined include:
This component defines a special kind of product that allows the structuring of trade by combining any number of products
within a strategy. A trade can be of a strategy rather than of a base product; this strategy can then in turn contain other
products, such as multiple options. For example, you could define a strategy consisting of an FX call and an FX put to create
a straddle or strangle, and then create a trade of that strategy.
The Strategy component makes use of a composition pattern since strategy itself is a product. This means that strategies can
themselves contain strategies.
A necessary feature of a portable data standard is both an agreed set of elements and an agreed set of permissible values
(the value domain) for those elements. An FpML document exchanged between two parties would not be mutually understandable
if either or both of the parties used internal or proprietary coding schemes to populate elements. For FpML 4.0 WD#2 the
handling of coding schemes has changed from previous versions of FpML, with the introduction of the use of enumerations and
the elimination of scheme default attributes from the FpML root element. The following description refers to the updated
approach.
One possible means of identifying value domains is to include the domain of permitted values within the schema, using an XML
Schema enumeration structure. This mechanism has been adopted in WD#2 for element values that satisfy the following criteria:
The list of allowable values is relatively short.
The list of allowable values is not expected to change during the lifetime of the specification
It's not possible to change the list of allowable values without affecting the meaning of the specification.
This leave a number of lists of values not meeting the above criteria that are represented by "schemes". "Schemes" are lists
of values that can be changed dynamically without affecting the schema. They include items such as currency codes, party
identifiers, business centers, floating rate indexes, etc. For these data elements, the "scheme" is a URI, as identified
in an FpML attribute, that designates the universe of acceptable values the element may take. This scheme definition list
is typically encoded as an XML document, but does not in general need to be. In cases where the ISDA wishes to designate
a default scheme, this is recorded as a default attribute value in the schema. In other cases, the scheme attribute is required.
For further details on the architectural framework behind Schemes, refer to the FpML Architecture Version 1.0 document.
Producers of FpML documents intended for interchange with other parties must encode such documents using either UTF-8 or UTF-16.
Consumers of FpML documents must be able to process documents encoded using UTF-8, as well as documents encoded using UTF-16.
For more information, see
The FpML 4.0 Schema is the first release of the specification to place a messaging framework around the product descriptions
to describe the context and use to which the information is expected to be put. This section describes a small set of complex
types and elements that comprise a simple message framework that is used as the basis for defining business messages suitable
for use in a 'Business-to-Business' (B2B) or 'Application-to-Application' (A2A) communications process.
These definitions introduce a new set of ideas that previously could not be used in FpML because of its reliance on DTDs as
the formal specification of the grammar. The following sections describe the reasoning behind the features used in the framework.
In general computer systems commonly use two styles of messaging to exchange information between each other, namely:
Request/Response
A style of exchange in which one system sends a message to the other to asking it to perform some function, the result of
which is encapsulated in an appropriate response and returned.
Notification
A style of exchange in which a system sends a message describing a business event that has occurred and may be of interest
to others.
The receipt of either kind of message may cause additional messages to be generated and sent as part of the processing to
obtain information from other systems or to inform them of the business event underway.
The FpML 4.0 schema explicitly models 'delivery' related information as part of the message itself. Some transports (i.e.
SOAP, ebXML, etc.) allow such information to be placed in the 'envelope' that surrounds the message during delivery whilst
others (e.g. message based middleware, files, etc.) do not.
Including a standard header within FpML messages increases consistency by providing a single format for delivering information
regardless of the physical transport, ensures that it will be persisted if the message is archived, and allows more flexible
use of features such as digital signatures.
The design of a grammar must strike a balance between the degree of flexibility it allows and the complexity of its validation.
An overly lax grammar allows the construction of documents that, whilst syntactically correct, may have no valid business
interpretation. On the other hand a very rigid grammar may require many more grammatical productions in order to enumerate
only the valid combinations.
In general it makes sense for a grammar to be strict when it can be achieved easily and without too much additional definition,
and lax where flexibility is required (e.g. for proprietary extensions, etc.). In the case of the message framework the grammar
provides a mechanism for ensuring that messages have the correct content that applies to them.
The receiver of a message needs to be able to determine the function that the message is invoking. In XML there are three
different techniques that can be used for indicating the purpose of a message.
The FpML message framework is based on type substitution as it gives the greatest control over validation whilst allowing
easy extension of the message elements.
The receiver can look at the namespace from which the element definitions have been drawn and determine from it the function
requested.
<?xml version="1.0"?>
<FpML version="4-0"
xmlns="http://www.fpml.org/2002/FpML-4-0-TradeConfirmationRequest">
<header>
... Message header
</header>
... Business data
</FpML>
Using namespaces it would be possible to create a highly extendable framework for FpML but it could lead to documents having
to have every FpML element prefixed with a suitable namespace abbreviation although it may be possible to mitigate this by
having the 'core' sub-schemas use no namespaces in their definition and take on the namespace of the one they are including
into.
There may be further issues with related XML standards such as XPath as the namespace of the same included elements may not
be consistent between documents.
The receiver can look at the name associated with an element within the message (either the root or one of the first level
children) to determine the function requested.
<?xml version="1.0"?>
<FpML version="4-0" xmlns="http://www.fpml.org/2002/FpML-4-0">
<header>
... Message header
</header>
<tradeConfirmationRequest>
... Business data
</tradeConfirmationRequest>
</FpML>
To ensure that the content of the FpML element is always a valid message element the grammar would have to use either a choice
group (which would limit extensibility) or a substitution group (which is extensible) to define the acceptable elements.
Whilst the root element could be used to indicate the function it is more likely that a child would be used so that all FpML
documents would still have the FpML element as the root.
In this model the message header must be generic, that is suitable for any kind of message. There is no way in XML to validate
that the content is suitable for the type of message content that follows.
The receiver can look at the type associated with an element within the message (e.g. the root or a child).
<?xml version="1.0"?>
<FpML version="4-0" xmlns="http://www.fpml.org/2002/FpML-4-0"
xsi:type="TradeConfirmationRequest">
<header>
... Message header
</header>
... Business data
</FpML>
An XML schema based instance may use type substitution to replace the content model of any element with another providing
that the replacement is derived from the original. Given a framework that provides the appropriate extension points any number
of new types can be derived within the name or different namespaces as necessary.
In addition through inheritance the message types can be associated with an appropriate message header content model.
This section documents the definitions included in the FpML 4.0 schemas that implement the message framework.
Note that the schema diagrams in this section do not show the standard attributes (e.g. version, scheme defaults, etc.) normally
associated with the FpML element to reduce the size of the images. Consult the XML schema to see the full definitions of these
types and elements.
The two core definitions within the schema establish two abstract base classes, 'Message' and 'MessageHeader' from which all
the other definitions are derived.
The 'Message' type contains a single element 'header' that holds the message identification and delivery data defined by the
'MessageHeader' type. The Message type inherits the set of attributes used to identify the FpML coding schemes by extending
the Document type. The elements that comprise a 'MessageHeader' are the superset of elements required for both request/response
and notification messaging styles.
The following XML schema fragment shows how these types are defined.
Not all of the elements of 'MessageHeader' are relevant to all messaging styles and its content is restricted by subsequent
definitions, The role of each element is given below.
conversationId allows a message sender to create a common context for a number of separate message exchanges.
messageId contains the senders unique identifier for a message.
inReplyTo contains the unique identifier for the request message that is being responded to.
sentBy identifies the party sending a message.
sendTo identifies the parties who will receive a message and should act upon it.
copyTo identities other parties who will receive a message but who do not have to act upon it.
creationTimestamp describes the time when the sender created the message.
expiryTimestamp defines a time after which the sender will consider the message expired.
dsig:Signature allows the inclusion of W3C digital signatures within the message.
The schema derives three abstract message style types from the core messaging classes by restriction. For example a request
message may not have an inReplyTo element where as it is made mandatory in a response.
The following image shows the construction of just one message style type, as with in the exception of the type of the header
element, they are all the same.
In each case inheritance is used to restrict the content model of the base 'Message' type and change the type of the 'header'
element. Each of these types is in turn a restriction of the generic 'MessageHeader' type with some elements excluded or made
mandatory.
FpML releases to date have concentrated on defining only product structure. These products are the key part of many messages
but in order to have a meaningful 'conversation' additional information is required to express the action that the message
sender believes the message receiver should perform upon receipt of the message. Usually a key data structure like a product
and/or party is the main component of the data that accompanies the request but for some actions additional parameters may
need to be included.
Within the context of FpML, trade affirmation is considered to be a notification of trade execution. An affirmation message
may be sent internally or externally after the trade negotiation has completed. At this point the trade may not have been
legally confirmed between the two principal parties. Trade affirmations may also be sent by a third party, e.g. a broker,
to the principal parties involved.
There are a few basic patterns that are used in the industry today for delivery of trade affirmation messages. In all cases
the workflow is basically the same. That is, a notification message is sent from a trading system (either an internal/external
system or broker) followed by an acknowledgement of receipt (response message) from the message receiver. Acknowledgement
of receipt is used to complement the asynchronous nature of the affirmation message and to assure that the message is not
deleted from the originating system prior to being persisted in the destination system.
The following sequence diagram illustrates the process for one side of a bilateral affirmation. Both parties to the trade
may be executing this process to obtain an affirmation from each other.
The affirmation message typically contains the same information that is contained in a trade confirmation message. Some details,
such as settlement information, could be omitted if it is unknown to the affirmation sender. The following diagram shows the
content model for a 'TradeAffirmation' message.
The response to the affirmation message indicates its acceptance and indicates the transaction to which it applies. The content
model for it is as follows:
If the trade affirmation is being generated by a third party, such as a broker, then affirmation could be sought from one
side and then the other, or from both simultaneously as shown in the following diagram.
The data content of the messages is the same as in the bilateral case.
Today the procedure for achieving trade confirmation is manual for most OTC derivative transactions. Principally this is because
the information describing the economic and legal liabilities of the transaction are embedded within a native text document
and set amongst legal wording. A skilled human reader is needed to extract and compare the relevant information to determine
if it matches the bank's own definition of the same deal.
This section describes how the process of trade confirmation for OTC derivatives might be achieved electronically through
the exchange of a sequence of 'messages' between the two parties' computer systems. This can only take place if the parties
involved have identified and 'marked-up' the salient details of the transaction using a common vocabulary of terms and data
structure, such as those provided by the FpML product definitions.
There are two common styles for trade confirmation used by the finance industry today:
Bilateral confirmation models the current manual process where one party (the confirmation requester) creates a legal definition
of the trade, signs it and sends it to the other party (the confirmation provider) who checks and then countersigns the document
and returns it.
This countersigned document becomes the legally binding definition from the transaction once it has been acknowledged back
to the requester.
Both parties might be attempting to obtain a confirmation from the other with this method at the same time.
Trilateral confirmation involves both parties to a trade each generating and sending a copy of the agreed upon trade to an
independent third party. When the third party determines that two trades match it sends an identical trade representation
to both parties to confirm the match.
The trade description generated by the confirming service becomes the legally binding trade representation.
Matching and comparison are central to confirmation process. In basic terms the matching operation is carried out as follows.
Each new request to confirm a trade results in a search of the system's set of currently unmatched trades to determine if
a viable match exists. A trade is comprised of a set of data items that describe its properties and each one of these in turn
falls into one of following three categories:
Identifying financial items that, if present, must exactly (or within tolerance) match (e.g. common trade identifier, trade
date, maturity, product type, currencies, notional amounts, parties, etc.).
Non-identifying items that should exactly (or within tolerance) match (e.g. business centers, date roll conventions, etc.).
Items irrelevant to the matching process (e.g. comments).
As a result of the matching process a trade is said to be:
Matched - If all identifying and non-identifying items agree.
Mismatched - If all identifying items agree but the non-identifying items differ.
Unmatched - No match on identifying items could be found.
If a trade is matched then both descriptions of a trade are fully reconciled and the parties can agree that it is confirmed.
If the trades contain identification information that shows that they should have matched but other significant details differ
then the trade is mismatched.
If no match was found then the system must assume that it is yet to receive a copy of the trade from the other party and should
add it to the set of unmatched trades and wait for the next request.
Some additional actions are required to prevent trades remaining unmatched indefinitely. There are two cases that can give
rise to this situation:
The counterparty failed to enter and send his definition of the transaction (so no counter-trade exists in the system).
The counterparty incorrectly identified the true party (in which case a counter-trade exists but will never match).
To attempt to recover from both cases after a trade has remained unmatched for a period of time, the system should send a
message to the alleged counterparty in order to provoke them into investigating whether they need to send a new trade or correct
an existing unmatched trade.
If after an additional time period the trade still remains unmatched, it should be returned as failed.
This document assumes throughout that the delivery of a message is guaranteed by the transport used to send it. If some communication
error occurs that prevents delivery or causes the temporary loss of messages we shall assume that it is the transports responsibility
to re-establish connection at a later time and resume communication from the point of failure.
If the message cannot be processed for some technical reason such as: it has become corrupted, is not XML or is not a valid
FpML message, then the receiver returns a 'MessageRejected' message to the sender. Usually the message will require manual
intervention to diagnose and solve any problems. Such rejections will not be show on any of the diagrams in this paper.
If the message cannot be processed because the request is invalid, given the state of the data to which it applies, then an
appropriate business level notification is returned to the sender (e.g. 'TradeNotFound', 'TradeAlreadyMatched', etc.) which
in turn could be used to invoke either an automatic recovery or a manual intervention.
The design of the rejection message must allow for the inclusion of a computer readable error code (taken from a standard
list) as well as some location information for the source of the error (e.g. a XPath expression) and a copy of the failed
message. The following diagram shows a possible message design for this.
In order to encapsulate one XML message within another the addition data section would have to use an XML CDATA encoding to
prevent the parser from attempting to process the contents.
The following sections illustrate the end-to-end sequence of message exchanges required to confirm a transaction directly
between two parties and the various outcomes that are possible.
Under normal operation we would expect a match to be found as soon as both the internally and externally generated copies
of the trade are submitted to the confirmation engine.
Following a trade negotiation each side generates a 'RequestTradeConfirmation' message which is sent to the confirmation provider's
system. These requests are used to initiate a trade matching operation. The structure of the request message is shown below.
If the request is valid then the trade is passed to the matching engine for processing. The 'RequestTradeMatch' message needs
the same basic data content as the confirmation request message.
When a match is found the associated notification message needs to identify the two trades (via their identifiers) to the
participants.
To finish the process the confirmation requestor confirms his acceptance of the match by issuing a 'ConfirmTrade' message
that contains a reference to the matched trade.
The final notification of the confirmation provider reiterates the legally binding definition of the trade.
If the request contains the details for a transaction which has already been processed by the confirmation service then a
number of possible errors can result in response to the request:
If a request to confirm the same trade was made previously and the trade is currently unmatched or mismatched, then the service
should reply with a 'TradeAlreadySubmitted' message.
The 'TradeAlreadySubmitted' message has the following content model:
If a request to confirm the same trade was made previously and the trade was successfully matched, then the service should
reply with a 'TradeAlreadyMatched' message.
The 'TradeAlreadyMatched' message has the following content model:
If a mistake has occurred in the generation of one trade confirmation request it is possible that the system can detect that
two trades should have matched (e.g. they contain a common unique trade identifier) but that they cannot due to significant
differences.
The confirmation system keeps trades in its pool following the mismatch notification to allow a subsequent correction or cancellation
to be applied to the trade.
The 'TradeMismatched' notification must contain the participants trade identifier as well as the identifier for the counter-trade
that it should have matched, together with any other potential matches.
Whilst a trade is unconfirmed the requesting party may send new copies of the transaction data to replace the original trade
details. The data content of the replacing transaction should match the same requirements as those for initiation. Transactions
must be fully re-specified (rather than just the incremental differences). The content model for the 'ModifyTradeConfirmation'
message which requests this is as follows:
There are a number of scenarios that can result in the processing of such messages:
The confirmation system may not be able to locate the original trade description to be modified.
The generated 'TradeNotFound' message contains the identifier for the trade the system was unable to find.
The modification may be accepted and propagated to the matching engine but the trade remains unmatched.
As with the initial matching request the 'ModifyTradeMatch' message contains a full copy of the trade.
The modification may be accepted and propagated to the matching engine resulting in a mismatched trade.
The modification may be accepted and propagated to the matching engine resulting in a matched trade.
Whilst a trade is unconfirmed the requesting party may ask the entire confirmation action to be cancelled. The cancellation
message needs only to contain the information necessary to identify the transaction it affects and must match a currently
unconfirmed transaction.
As in earlier cases there are a number of possible processing scenarios depending on the state of the trade within the confirmation
system, namely:
If the cancellation applies to a trade that can not be located, then the sequence of messages is as follows:
If the cancellation applies to an existing unmatched trade then, it generates the following messages:
Once the confirmation system has identified the trade as unmatched it must request that the matching system remove the trade
from its storage. This is done through a 'CancelTradeMatch' message.
The response to the confirmation requester completes the process by acknowledging that the confirmation request is cancelled.
If the cancellation applies to a trade which has already been matched, then the message flow is as follows:
When the confirmation provider detects an unmatched trade that has been outstanding for a period of time, it sends a copy
of the transaction to the indicated counterparty. The trade is not removed from the unmatched trade set so that a subsequent
new trade confirmation or modification request may match against the trade.
The 'TradeAlleged' message must provide the identification information for the transaction that is alleged against the counterparty.
A confirmation service might provide additional information to suggest current unmatched trades that might be a counter transaction.
A request for trade confirmation that remains unmatched, even after alleged trade processing, for a length of time, should
be returned to the requester within a message indicating a failure to match.
The 'TradeUnmatched' notification contains identification information for the unmatched trade and may contain suggestions
for possible counter trades.
This section illustrates some processes in action with a third party performing the matching process. In general the sequence
of requests and responses is the same as in the bilateral case and there are no additional trilateral specific message types.
As before the confirmation process is begun when the trading parties send a description of the trade to the confirmation system,
now external to both parties.
The presence of the third party allows the match to be taken as legally binding and it is automatically considered confirmed
without the need for any further messages.
If the request contains the details of a transaction that has already been processed by the conformation service then a number
of possible errors can result from the request, namely:
If the trade has already been submitted and is currently unmatched or mismatched the service should reply with a 'TradeAlreadySubmitted'
message.
If the trade has already been processed and has been matched, then the service should reply with a 'TradeAlreadyMatched' message.
As in the bilateral case either party can request that the details of an unmatched trade be replaced with a new definition.
The series of scenarios are identical to the bilateral cases.
If no corresponding trade can be found in the confirmation system then a 'TradeNotFound' messags is generated.
The modification may be accepted and propagated to the matching engine but the trade remains unmatched.
The modification may be accepted and propagated to the matching engine resulting in a mismatched trade.
The modification may be accepted and propagated to the matching engine resulting in a matched trade.
As in the bilateral case either party can request that the confirmation processing for an unmatched trade be suspended and
the trade definition removed from the set of unmatched trades.
If the cancellation applies to a trade that can not be located, then the sequence of messages is as follows:
If the cancellation applies to an existing unmatched trade, then it generates the following messages:
If the cancellation applies to a trade which has already been matched, then the message flow is as follows:
As in the bilateral case any trades that remain unmatched, even after alleged trade processing has been attempted, are eventually
removed from the unmatched trade set.
At a number of points in the confirmation process it is possible that one or the other or both parties to a transaction received
an unexpected error message from the other or the central service.
In order to determine the correct course of action to recover from such an error the participants need to determine the perceived
state of their transaction within the other party's systems. This indicates that a simple status enquiry operation would be
required to recover the necessary information.
For efficiency the trade status enquiry message should allow more than one transaction to be checked at a time (e.g. all outstanding
unmatched trades, etc.). Its content model is as follows:
The response message returns each identifier with a suitable status code value (i.e. unmatched, matched, confirmed, not known,
etc.).
A swap component contains one or more instances of the swapStream component, zero or more instances of the additionalPayment
component together with an optional cancelableProvision component,an optional extendibleProvision component and an optional
earlyTerminationProvision component. A swapStream contains the elements required to define an individual swap leg.
Within an FpML swap there is no concept of a swap header. Details of payment flows are defined within swapStreams which each
contain their own independent parameters. There can also be additionalPayment elements that contain fees. The additionalPayment
component is identical to the otherPartyPayment component shown above.
FpML also supports option related features. These include cancelable, extendible swaps and early termination provisions. Combining
these together with swaptions into a single component was considered but rejected in favour of identifying the different option
types with their own components. This provided more clarity and allowed for easier combination of the different options into
a single trade. As such a swap can contain a cancelableProvision, extendibleProvision and an earlyTerminationProvision. All
these components are very similar (and similar to the swaption component), re-use is achieved by using shared entities within
each of the components.
FpML supports two representations of a swap stream; a parametric representation, and a cashflows representation. The parametric
representation is designed to capture all the economic information required regarding dates, amounts and rates to allow trade
execution and confirmation. The parametric representation is mandatory. The cashflows representation specifies an optional
additional description of the same stream. The main purpose of this is to allow the inclusion of adjusted dates within an
FpML representation of a trade. It can also be used to represent adhoc trades not achievable by easy manipulation of the parameters
of a stream (i.e. by changing the adjusted dates). This would lead to the cashflows not matching those generated by the parameters
(see more discussion later) and would also render the representation of the trade unsuitable for a confirmation. The spirit
of FpML is that such manipulation of cashflows would be achieved by splitting a single stream into a number of streams though
it is recognized that this may be impractical in some systems.
The cashflows representation is not self contained as it relies on certain information contained within the stream's parametric
definition. The elements required from the parametric definition to complete the cashflows representation are:
The following elements and their sub-elements within the calculationPeriodAmount element:
floatingRateIndex
indexTenor
rateTreatment
finalRateRounding
averagingMethod
negativeInterestRateTreatment
dayCountFraction
discounting
compoundingMethod.
The following elements and their sub-elements within the stubCalculationPeriodAmount element:
floatingRateIndex
indexTenor.
The inclusion of the cashflows representation is intended to support Application integration. For example, a financial institution
may have one application that captures trade parameters and constructs the trade schedules and then publishes the result for
use by other applications. In this case it may be either undesirable, or impossible, for each of the subscribing applications
to store and calculate schedules.
The flexibility of the cashflows representation also allows payment and calculation schedules which can not be fully represented
by the parametric description. If this situation arises, the mandatory parametric data should still be included in the document
and the flag cashflowsMatchParameters should contain the value false to indicate that it is not possible to generate the cashflows
from this parametric data. The setting of this flag to true means that the cashflows can be regenerated at any time without
loss of information.
Parties wishing to take advantage of the facility for specifying cashflows which are inconsistent with the parametric representation
will need to specify additional rules for how the parametric representation should be processed. This applies to both the
creation of the parametric data as well as its interpretation.
The cashflows representation specifies adjusted dates, that is, dates that have already been adjusted for the relevant business
day convention using the relevant set of business day calendars (lists of valid business days for each business center).
The FpML standard does not specify the source of these business day calendars. This may lead applications to generate differing
cashflow representations from the same parametric representation if they use different business day calendars. The use of
adjusted dates also produces schedules that are only valid at a particular instance of time. Additional holidays for a business
center may subsequently be introduced that would result in changes to the adjusted dates, which would not be reflected in
the cashflows representation.
Analogous to cashflows being used to represent adjusted dates, with the addition of options it was important to be able to
represented the adjusted dates associated with an option. Thus, where appropriate, a component includes an optional element
to represent a schedule of adjusted dates for the option. Such a schedule would include details of adjusted dates such as
adjusted exercise dates and cash settlement dates.
In general, an interest rate swap will be a swap with a fixed leg and a floating leg, two floating legs, or two fixed legs.
However, certain types of trades may contain more than two legs. FpML does not restrict the number of legs that may be defined.
From a modeling perspective, FpML does not distinguish between a swap leg referencing a fixed rate and a swap leg referencing
a floating rate, the difference being indicated by the existence, for example, of the resetDates component in a floating rate
leg.
The structure of a swapStream is shown diagrammatically below:
The components within a swapStream cannot be randomly combined and cannot be thought of as existing in their own right; they
only make sense in the given context and in relationship to other components within the swapStream container.
In FpML, the schedule of dates within a swapStream is based around the calculationPeriodDates component. The definition of
a calculation period in FpML differs in some respects from the International Swaps and Derivatives Association (ISDA) definition
of Calculation Period. In the case of a trade involving compounding, ISDA introduces the concept of a Compounding Period,
with several Compounding Periods contributing to a single Calculation Period. The FpML calculation period is equivalent to
the ISDA definition of Compounding Period when compounding is applicable, i.e. the calculation period frequency will correspond
to the compounding frequency. An FpML calculation period is directly comparable to the ISDA defined Calculation Period when
only one calculation period contributes to a payment.
The other date components within swapStream are related to the calculationPeriodDates component. The paymentDates and resetDates
components contain the information necessary to construct a schedule of payment and reset dates relative to the calculation
period dates.
FpML uses the ISDA Floating Rate Option to specify the floating rate being observed. This scheme was used rather than attempting
to parameterize into elements because although most floating rate indices are defined fully by a standard set of parameters
(namely index, currency and fixing source) there are sometimes other details including fixing offsets and formulas. This approach
allows for more flexibility in adding new floating rate indices without having to introduce new elements, although this comes
at the expense of a self contained definition within the standard.
The information relating to amounts and rates is collected in the calculationPeriodAmount and stubCalculationPeriodAmount
components. fxLinkedNotionalSchedule is an alternative to notionalSchedule for defining notionals. This allows for the definition
of FX Resetable trades by allowing for the notional of a stream to be linked to notionals from another stream by way of the
spot fx rate.
Certain swapStream components are designated as being optional (although it would be more accurate to say that they are conditional).
Thus a fixed rate stream never includes a resetDates component, but this is required for a floating rate stream. Similarly,
the stubCalculationPeriodAmount component will be required if the swap leg has either an initial or final stub, or indeed
both, but should otherwise not be specified. The principalExchanges component is required in the case of cross currency swaps
or other types of swap involving exchanges of principal amounts.
The payerPartyReference and receiverPartyReference elements indicate which party is paying and which receiving the stream
payments. This is done by referencing the appropriate party within the party component.
The detailed structures within the swapStream are shown diagrammatically below:
As noted above, the definition of a forward rate agreement trade is contained within a single component. A forward rate agreement
is a simple and commoditized product. This means there is no variation in the product traded and it is not expected to become
more complex in the future.
The structure of the fra component is shown diagrammatically below:
FpML also supports interest rate options. The supported components are:
Early Termination Provision (Optional or Mandatory) for a swap
Cancelable Provision for a swap
Extendible Provision for a swap
Swaption
Cap / Floor
The ISDA 2000 Definitions have been followed closely in defining the various option dates and element names. Thus components
for European, Bermuda and American exercise have been defined which are re-used in each of the first four components above.
These components share an element called relevantUnderlyingDate whose meaning is dependent on the option component it is contained
in:
OptionalEarlyTermination - It represents the new terminationDate of the underlying swapStreams if the trade is terminated
early.
CancelableProvision - It represents the new terminationDate of the underlying swapStreams if the trade is cancelled.
ExtendibleProvision - It represents the new terminationDate of the underlying swapStreams if the trade is extended.
Swaption - It represents the effectiveDate of the underlying swapStreams if the swaption is exercised.
This is a style of option to which the right or rights granted are exercisable on a single date referred to as the expiration
date. This date can be specified either as an adjustableDate or as a relativeDate though the latter is only expected to be
used in the case of cash settled cancellations where the expiration date may be defined as an offset to the cash settlement
payment date.
The relevantUnderlyingDate is optional, in its absence the effectiveDate of the underlying is the effectiveDate defined in
the swapStreams. This can only be excluded for european swaptions.
This is a style of option to which the right or rights granted are exercisable during the exercise period which consists of
a period of days. The underlying should specify its effective date based on the earliest possible exercise. When exercise
implies a stub period this will be taken to be a short stub at the start, i.e. the underlying swap defines a series of flows,
exercise merely brings the flows into existence from the relevantUnderlyingDate.
This is a style of option to which the right or rights granted are exercisable during an exercise period which consists of
a number of specified dates. These dates can be defined as a list together with adjustments or by reference to an existing
schedule elsewhere in the trade (e.g. resetDates). In the latter case bounds can be placed on the referenced schedule to define
a subset of the whole schedule.
The right for one or both parties to terminate the trade and settle the remaining term of the swap for fair value. In the
case of a mandatory early termination the termination is mandatory.
With a cancelableProvision the seller grants the buyer the right to terminate all swapStreams, typically in exchange for an
upfront premium. Unlike optionalEarlyTermination, the cancellation of the swap does not require the parties to exchange a
cash settlement amount on exercise representing the fair value of the remaining life of the swap although an exercise fee
can be specified in the exerciseFeeSchedule.
With an extendibleProvision the seller grants the buyer the right to extend all swapStreams, typically in exchange for an
upfront premium. This provision is very similar to a cancelableProvision and in fact the two share the same market risk profile.
FpML makes a clear distinction between the two since the operational risk associated with mis-recording the type of applicable
provision can be high. For example, a 10 year swap with the right to cancel after 5 years has exactly the same risk profile
as a 5 year swap with the right to extend for 5 years after 5 years. However, failing to give notice of exercise after 5 years
will in one case (extendibleProvision) result in the swap terminating after 5 years and in the other case (cancelableProvision)
result in the swap terminating after 10 years, i.e. action after 5 years is required in one case to lengthen the term of the
swap in the other to shorten it.
The option to enter into a swap is defined as its own product and contains the underlying swap as a swap element. A swaption
straddle is defined by setting the swaptionStraddle element to true: this implies that the swaption buyer has the right, on
exercise, to decide whether to pay or receive fixed on the underlying swap. If the underlying does not contain a single fixed
stream and a single floating stream then the straddle is invalid and thus this flag should be set to false..
Caps and Floors are defined as one or more capFloorStreams and zero or more additionalPayments. The capFloorStream re-uses
the FpML_InterestRateStream entity and thus its content is identical to a swapStream.
Though a capFloorStream allows the definition of fixed streams or known amount streams these are not the intended use of this
component and there use would be considered an invalid FpML trade.
The floatingRateCalculation component has been amended to allow the specification of cap/floor structures within a single
stream (e.g. straddles, corridors). The changes are:
The occurrence rules for the components capRateSchedule and floorRateSchedule have been changed from 'zero or one' to 'zero
or more'.
An optional buyer and seller reference have been added to these schedules
These additions allow for multiple cap and floor rates to be added to the stream and to define precisely which party bought
and sold them. To maintain backward compatibility with FpML1.0 the buyer and seller are optional. When absent the following
rules apply:
The cash settlement component is used by mandatoryEarlyTermination, optionEarlyTermination and swaption. The language used
within the component corresponds to the ISDA language for the various cash settlement methods. Of the five methods included,
three share one underlying component and the other two share another component. Thus there is re-use whilst maintaining ease
of identification of the type. Also, this approach allows for easy integration of other methods should they arise.
FpML 4.0 Credit Derivatives extends the product coverage of
FpML to include the credit default swap. In order to
define the scope of this work FpML adopted the definition of the credit default
swap used in the ISDA Year End 2001 Flash Survey:
In a credit default swap one counterparty
(the protection seller) agrees to compensate another
counterparty (the protection buyer) if a specified company or Sovereign
(the reference entity) experiences a credit event, indicating it is or may be
unable to service its debts. The protection seller is paid a fee and/or
premium, expressed as an annualized percent of the notional in basis points,
regularly over the life of the transaction.
The FpML 4.0 Credit Derivatives Product Architecture draws heavily on
the 2003 ISDA Credit Derivatives Definitions (hereafter referred to as
the "2003 Definitions"). Wherever
feasible the terminology and practice of the ISDA definitions has been adopted
to ensure consistency between traditional and FpML contract representation.
Appendix A lists the elements in FpML 4.0 Credit Derivatives that differ in
name from their corresponding terms in the 2003 Definitions.
The FpML 4.0
Credit Derivatives Subschema supports both a full confirmation and a
transaction supplement (i.e. economics of the trade) representation of the
credit default swap. The transaction supplement representation is a subset of
the elements contained in the full confirmation representation. This flexible
approach makes FpML 4.0 Credit Derivatives useable in all stages of the credit
default swap trade lifecycle.
This document
provides an in-depth review of the technical architecture of the FpML 4.0
Credit Derivatives Subschema.
Like all other
derivative products supported by FpML, the type used to represent the credit
default swap, CreditDefaultSwap, is defined as an extension of the Product type and the corresponding creditDefaultSwap element
belongs to the product substitution group. The creditDefaultSwap element appears in Figure 1.
Figure 1: creditDefaultSwap element
The structure of
the creditDefaultSwap
element corresponds to the structure of the
Confirmation that appears in Exhibit A of the 2003 Definitions (hereafter
referred to as the
"2003 Confirmation").
The six sections that comprise the 2003 Confirmation and their
corresponding FpML elements appear in Figure 2.
2003 Confirmation
FpML creditDefaultSwap Element
General Terms
generalTerms
Fixed Rate
Payments
feeLeg
Floating
Payment
protectionTerms
Settlement
Terms
settlementTerms
Notice and
Account Details
N/A
Offices
N/A
Figure 2: Sections of the 2003 Confirmation and their
corresponding FpML creditDefaultSwap elements.
Additional
points to note:
The id attribute and the productType and productId elements are inherited from the product type. They are not credit derivatives
specific. Each product supported by FpML contains these elements.
Although Settlement
Terms are specified on a full confirmation, they are not necessarily
required for a transaction supplement or other activities in the trade
lifecycle. Therefore, this element is optional in FpML 4.0.
The Notice and
Account Details and Offices sections of the confirmation do not
have a direct analog in the FpML 4.0 definition of the credit default
swap. In FpML, the party elements that appear under the FpML root element serve the purpose
these sections do in the traditional confirm.
The
remainder of this document reviews each child element of the
creditDefaultSwap
.
The generalTerms element, which appears in Figure 3, represents the information
specified in the General Terms section of the 2003 Confirmation.
Figure 3: generalTerms Element
The effectiveDate element represents the Effective Date term. In order to allow the explicit specification of a particular business day convention per the 2003 Definitions this element
is of type AdjustableDate.
The scheduledTerminationDate element represents the Scheduled Termination Date term. This element has a type of AdjustableOrRelativeDate. For confirmation purposes a specific date will always be specified.
Again, the AdjustableDate type allows the parties to explicitly specify a particular business day convention per the 2003
Definitions. The RelativeDate type (e.g. 5 Y for a five year deal) is included because this way of expressing a scheduled
termination date is quite commonly used in the pre-trade process and also in historical price databases.
The sellerPartyReference element represents the protection seller. This party is referred to as the Floating Rate Payer in the 2003 Definitions. Similarly, the buyerPartyReference element represents the protection buyer and is referred to as
the Fixed Rate Payer in the 2003 Definitions. These elements reference the party elements underneath the FpML root element.
The optional elements dateAdjustments.businessCenters and dateAdjustments.businessDayConvention are used to represent the
terms Business Day and Business Day Convention respectively.
The full expansion of the referenceInformation element appears in figure 4. Two of its child elements, referenceEntity and
referenceObligation, are used to represent the Reference Entity and Reference Obligation(s) terms respectively.
The referenceEntity element is of type LegalEntity and is required. The LegalEntity type requires an entityName and/or an
entityId to be provided. Both the entityName and the entityId are represented using schemes, which allow the source (e.g.
reference database) of the information to be recorded.
A referenceObligation element has either a bond or a convertibleBond as one of its child elements. The bond and convertibleBond
elements are shared FpML elements. In other words, they were not created specifically to support credit derivatives and are
also
used in other asset classes. For a credit default swap one of these elements is
used to specify a Reference Obligation's CUSIP/ISIN, Maturity and
Coupon values. The instrumentId element is used to specify CUSIP/ISIN. The optional instrumentIdScheme is used to specify whether the id provided is a CUSIP or an ISIN. Since multiple occurrences
of instrumentId are allowed, the schema
supports the specification of both the obligation's CUSIP and ISIN, if they
both exist. The couponRate and maturity elements are used to represent the Coupon
and Maturity terms respectively.
To represent the Primary Obligor term a referenceObligation element may optionally have either a primaryObligor or a primaryObligationReference element. If
the Primary Obligor is the Reference Entity, then primaryObligorReference should be used. Its href attribute will contain the id attribute of the referenceEntity. Otherwise,
the primaryObligor element, which is of type LegalEntity, should be used.
Similarly, to represent the Guarantor term a referenceObligation element may optionally have either a guarantor or a primaryObligationReference
element. If the Guarantor is the Reference Entity, then guarantorReference
should be used. Its href attribute will contain the id attribute of the referenceEntity. Otherwise, the guarantor element,
which is of type LegalEntity, should be used.
The optional allGuarantees and referencePrice are used to represent the
terms All Guarantees and Reference Price respectively.
Figure 4:
referenceInformation element
Although the structure of
referenceInformation
appears to be somewhat complex, the specification of Reference Entity and
Reference Entity information in FpML documents is quite simple, straightforward
and flexible. An example bears this out:
Reference Entity: Bundesrepublic Deutschland
Primary Obligor: Reference Entity
Guarantor: None
Coupon Rate: 5%
Date Maturity: 2012-7-4
ISIN/Cusip: DE0001135200
Reference Price: 100%
In order to support the full
credit default swap trade lifecycle, the schema allows this information to be
expressed in various degrees of detail:
Several
terms that appear in the General Terms section of the 2003 Confirmation
do not appear in the
generalTerms
element because
elements to represent these terms already existed in the FpML
trade
element.
The terms that belong to this category appear
in Figure 5 along with their corresponding FpML element.
The feeLeg element represents the information specified on in the Fixed
Payments section of the 2003 Confirmation. In other words, this is where the payment
stream from Fixed Rate Payer to the Floating Rate Payer is
specified. This element reuses types and elements from FpML 4.0 Interest Rate
Derivatives.
The
feeLeg
allows representation of these types of payment schedules:
Fixed Amount, Regular Schedule
Fixed Rate, Regular Schedule
Fixed Rate, Month-End Rolls
Fixed Rate, Initial (Short) Stub
Fixed Rate, Initial (Long) Stub
Fixed Rate, Final (Short) Stub
Fixed Rate, Final (Long) Stub
Fixed Amount, Single Payment
Upfront Fee and Fixed Rate, Regular Schedule
Irregular Payment Schedule
An optional cashflow representation is also permitted. The feeLeg
element appears in Figure 6.
Figure 6: feeLeg element
This structure allows specification of a
single payment (zero or more) or a periodic series of payments.
Therefore, it allows representation of a
single upfront payment, a single upfront payment combined with a schedule of
regular payments or a schedule of totally irregular payment dates and amounts.
The rollConvention
element is used to address the ambiguities that can otherwise occur
with regard to the actual payment dates, particularly when considering
month-end rolls and any initial stub. The
rollConvention
element typically takes a value of 1-30 or EOM.
It represents the actual unadjusted day in the month on which
payments would occur.
As in FpML 4.0 Interest Rate Derivatives, the
firstPaymentDate
element is only needed when the first period is irregular, i.e. there is a
short or long initial stub. For a regular set of payment periods knowing the
Effective Date, Scheduled Termination Date, payment frequency and roll
convention is sufficient to define the schedule.
In keeping with the 2003 Definitions either a
Fixed Rate Calculation or known Fixed Amount may be specified. The optional
dayCountFraction
element should be omitted in the case of a Transaction Supplement.
Similarly, the optional
calculationAmount
element provides support for the full confirmation but should be omitted in the
case of a Transaction Supplement.
The addition of the
adjustedPaymentDate
element within
singlePayment
and
adjustedPaymentDates
component in
periodicPayment
allows the optional inclusion of a 'cashflows' like structure
consistent with what it done in FpML 4.0 Interest Rate Derivatives. Note these
structures are intended more for internal application integration use rather
than external communication, i.e. wouldn't be
applicable for confirmations.
The
protectionTerms
element, which appears in Figure 7, represents the information
specified in the FloatingPayment section of the 2003 Confirmation.
This is where the credit events and
obligations that are applicable to the credit default swap trade are specified.
Figure 7: protectionTerms element
The
only required child element of
protectionTerms
is
calculationAmount.
It represents
the term Floating Rate Payer Calculation Amount in the 2003
Definitions.
The
actual Credit Events (e.g.
bankruptcy, failureToPay)
are of type
CreditEvent
or an extension
of it and belong to the
creditEvent
substitution group. In other words, in order
to indicate that a particular Credit Event is applicable in an FpML credit
default swap trade, an element whose name is the Credit Event it represents
appears as a child of the
creditEvents
element. If a
particular Credit Event has no attributes of its own (e.g. Bankruptcy),
it appears as an empty element. On the other hand, if
it does have attributes (e.g. Failure
to Pay - Grace Period, Payment Requirement) then those attributes appear as
child elements of the
creditEvent.
In the following example, these credit
events are applicable:
Bankruptcy
Failure to Pay with Grace Period Extension not applicable and Payment Requirement of USD 1,000,000.
Restructuring (R)
Default Requirement of USD 10,000,000.
And these conditions to credit event notice settlement
apply:
Both the Buyer and Seller are notifying parties.
Notice of Publicly Available Information
is a Condition to Payment - defaults apply for Public Source(s) and Specified
Number.
Please note the following regarding the representation of the Restructuring credit
event:
If the Restructuring credit event is not applicable, no
restructuring element should appear in the creditEvents element.
If Restructuring as defined in the 2003 Definitions is applicable and a full confirmation is being repesented, then the restructuring element
should appear and the restructuringType element contains one of the three restructuring codes (see below).
If Restructuring as defined in the 2003 Definitions is applicable and a transaction supplement is being repesented, then only the restructuring
element should appear (the actual restructuring type will be defined in the relevant master confirmation associated with the
transaction supplement).
The legal restructuring codes are:
ModR: If Restructuring Maturity Limitation and Fully Transferable Obligation (Section 2.32) applies.
ModModR: If Modified Restructuring Maturity Limitation and Conditionally Transferable Obligation (Section 2.33) applies.
R: If neither Restructuring Maturity Limitation and
Fully Transferable Obligation or Modified Restructuring MaturityLimitation and Conditionally Trasnsferable Obligation are
applicable.
The
optional
obligations
elements
has a
category
child element that represents the Obligation
Category term. The
ObligationCategory
type is an
enumeration that consists of values representing the following categories:
Payment
Borrowed Money
Reference Obligations Only
Bond
Loan
Bond or Loan
Obligation
Characteristics
are defined in a manner similar to credit events. In other words, each
Obligation Characteristic has its own element. The applicability of the
characteristic is indicated by the appearance of its corresponding
obligationCharactersitic
element.
If
settlement terms are specified in an FpML 4.0 credit default swap, then the
settlement method of Physical Settlement or Cash Settlement is
specified by the presence of either the
physicalSettlementTerms
element or the
cdsCashSettlementTerms
element respectively. Both
of these elements are of types that are extensions of
SettlementTerms
and that belong to the
settlementTerms
substitution group.
The
physicalSettlementTerms
element, which appears in
Figure 8, represents the information specified in the Settlement Terms-
Terms Relating to Physical Settlement section of the 2003 Confirmation.
The
physicalSettlementPeriod
contains one of three
elements to represent the following conditions:
businessDaysNotSpecified: Section 8.5/8.6 of the 1999/2003 CD Definitions applicable.
businessDays: Explicit number of business days.
maximumBusinessDays: Section 8.5/8.6 of the 1999/2003 CD Definitions capped at a specific number of business days, e.g. 10
days.
The
deliverableObligations
element is defined in a
manner very similar to the
obligations
element. The
only difference is that
deliverableObligations
contains a deliverableObligationCharac
element to represent those Deliverable Obligation Characteristics that
are not also Obligation Characteristics (e.g. Assignable Loan).
It also bears mentioning that the
applicability of Partial Cash Settlement appears as child element of the
corresponding
deliverableObligationCharac.
Figure 8: physicalSettlementTerms element
The
cdsCashSettlementTerms
element, which appears in
Figure 9, represents the information specified in the Settlement Terms-
Terms Relating to Cash Settlement section of the 2003 Confirmation. The
mapping between this element and its corresponding section of
the confirm is very straightforward. The only point to note
is some minor name changes were made due to collisions with existing FpML
elements of the same name, but a different type. These name changes are listed
in Appendix A.
There
are several places in the FpML 4.0 Credit Derivatives Subschema where the
element names diverge from the names used for terms in the 2003 Definitions.
These names are listed in the table that appear in
Figure 10.
Foreign exchange single-legged instruments include spot and forwards. fxSingleLeg contains two instances of the exchangedCurrency
component (the first currency and the second currency), either a single value date component for the trade or an optional
value date per exchanged currency, a single instance of the exchangedRate component, and an optional nonDeliverableForward
component.
The simple FX transaction contains two currencies which are exchanged between parties. The characteristics of each currency
exchange: the currency, the amount, and optionally settlement instructions, are described in the exchangedCurrency structure.
An optional payment date is allowed per currency, if there is a requirement to provide for date adjustments for each currency
based upon business day conventions to accommodate unscheduled holidays.
The rate of exchange is required for a foreign exchange trade. The rate of exchange includes a reusable entity (FpML_QuotedCurrencyPair)
that describes the underlying composition of the rate: the currencies and the method in which the rate is quoted. The actual
trade rate is required, but other rate information such as spot rate and forward points are also accommodated. For non-base
currency trades, side rates (or rates to base) are provided for.
Non-deliverable forwards are catered for within the conventional FX single leg structure by including an optional non-deliverable
information structure. This contains identifies the agreed-upon settlement currency and describes the fixing date and time,
as well as the settlement rate source that the fixing will be based upon. The non-deliverable structure is shown below.
Significant effort has been spent in the development of FX to incorporate the appropriate information required for trade confirmation
and settlement. An optional settlementInformation structure has been included for each exchanged currency. This can be used
in a variety of ways: not at all, flagging a trade for standard settlement, flagging a trade for settlement netting, or specifying
the detailed settlement instructions for that particular currency flow.
If the specific settlement instruction is included, then this is broken out into correspondent, intermediary, and beneficary
information. This includes the identificaiton of the routing mechaism (e.g., SWIFT, Fedwire, etc.) that the trade will settle
via and the id and account that the trade will settle via. Routing can be handled either via purely a routing id (e.g., SWIFT
code), routing details (a customer name, address, and account number), or a combination of routing id and details. The following
diagrams show the correspondent, intermediary, and beneficiary structures.
Split settlement is also accommodated. Split settlement will mean that there will be multiple beneficiaries associated with
a single trade, where the payment amounts are broken down between beneficiaries. The following diagram shows how this has
been modeled:
Foreign exchange swaps are a very simple extension of FpML_FXLeg, whereby the FX swap is simply multiple legs. A standard
FX swap contains two legs, whereby the second leg has a value date that is greater than the value date on the first leg.
There are a variety of different types of FX swaps in the marketplace: standard (round-amount) swaps, overnight swaps, unequal-sided
swaps, forward-forward swaps. Therefore, all of the features that are available within a standard spot or forward trade (described
previously) can be utilized in describing an FX swap as well.
Foreign exchange simple options include standard European and American options. These are commonly referred to as "vanilla,"
or non-exotic, options. fxSimpleOption identifes the put currency and amount and call currency and amount, as well as the
exercise style and premium information. The premium is structured similar to an exchanged currency for a conventional FX
trade, where optional settlement information for the premium can be attached. In addition, there is an optional quotedAs
structure that contains information about how the option was originally quoted, which can be useful. Below are the structures
for a conventional FX OTC option.
Non-deliverable options are also supported by including the FpML_CashSettlement, which is the identical structure used within
non-deliverable forwards.
A conventional option except that it is changed in a predetermined way when the underlying trades at predetermined barrier
levels. A knock-in option pays nothing at expiry unless at some point in its life the underlying reaches a pre-set barrier
and brings the option to life as a standard call or put. A knock-out option is a conventional option until the price of the
underlying reaches a pre-set barrier price, in which case it is extinguished and ceases to exist. Barrier options have both
a strike price and a barrier price.
An optionalbarrierTypeScheme is used to allow for differentiation between knockin, knockout, reverse knockin, and reverse
knockout options. One or more barriers are supported. The reference spot rate, while optional, is recommended, as it determines
whether the option need to go up or down (or is "out-of-the-money" or "in-the-money") in order to hit the barrier. Additionally,
the payout is utilized to accommodate rebates when a barrier is hit. Below are the structures for an FX OTC barrier option.
The terms binary and digital are not clearly defined in the FX markets and can occasionally be synonomous. This is used to
define an option that has a discontinuous payout profile. It typically pays out a fixed amount if the underlying satisfies
a predetermined trigger condition or else pays nothing. Unlike the standard option, the amounts quoted are the payout amounts
as opposed to a notional underlying amount.
Digital options typically are defined as being European, meaning the observation occurs only if the spot rate trades above
(or below) the trigger level on expiry date. The two examples that have been included in the specification are the digital
and the range digital.
Binary options, on the other hand, are more like American options, meaning that the payout occures if the spot rate trades
through the trigger level at any time up to and including the expiry date. The four examples that have been included in the
specification are the one-touch, no-touch, double one-touch, and double no-touch binary options. Below are the structures
for FX OTC binary and digital options.
Foreign exchange average rate options (sometimes referred to as Asian options) are options whose payout is based upon the
average of the price of the underlying, typically (but not necessarily) over the life of the option. Average rate options
are popular because they are usually cheaper than conventional options because the averaging process over time reduces volatility.
fxAverageRateOption allows for either a parametric representation of the averaging schedule (e.g., daily, 2nd Friday, etc.),
utilizing the same rolling convention schemes as utilized within the interest rate derivatives area. Alternatively, each
specific averaging period can be identified, along with a specific weighting factor for that period. In addition, average
rate options on occasion, when struck, already have agreed-upon rate observations in the past; the structure accommodates
this as well.
The term deposit is an agreement between two parties to enter into a financial contract. Similar to a forward rate agreement,
a term deposit is contained within a single component and contains no interim interest payments. It is an on-balance sheet
transaction that pays interest at maturity based upon an agreed interest rate. While the term deposit instrument is technically
an interest rate product, it is included within the FX section of FpML because many institutions that utilize FX transactions
also conduct short-term deposits in their respective portfolios to fund foreign currency requirements.
Although there are a number of structured deposits that are occasionally transacted in the marketplace, including deposits
with amortizing structure, rateset schedules, and periodic interest payment or interest recapitalization schedules, or even
deposits that are denominated in one currency but pay interest in another currency, those types of transactions represent
a significant minority of the number of deposits dealt in the wholesale financial marketplace. Therefore, the term deposit
structure is intentionally very simple to accommodate the simple yet highly liquid deposit instruments.
Note that both the start date and maturity date of the term deposit is negotiated up front and are typically of short duration,
so the dates of these instruments are fixed. Any unforeseen holidays will generally cause for renegotiation of the contract.
Therefore, similar to FX instruments, there are no allowances for date adjustments.
One or more financial instruments, of any sort that are supported by the FpML specification, can be combined to form what
is called a strategy. This can include various a package of the same or different asset classes in a single trade. Typical
examples of this would include option packages (e.g., straddles, strangles) or a delta hedge (FX OTC option with spot risk
hedged by FX spot deal). Additionally, other asset classes can be combined in a strategy (e.g., interest rate swap with FX,
etc.).
In FpML version 3.0 the equityOption component was defined to describe
"vanilla" options with the following characteristics:
put and call options;
with American or European exercise styles;
on single stocks or indices; and
delivery being either cash or physical stock.
For FpML 4.0 this component has been extended to encompass
more exotic types of options, including:
Bermudan exercise style;
basket underlyings;
forward starts;
quantos and composites;
averaging; and
barriers, knock-ins, knock-outs and binary (digital) options.
Many of the above can be combined through the use of a
single component architecture that has a number of optional features.
Compound options (such as Butterfly and Straddle structures) can be
represented by combining two or more equityOption components in a
strategy component. In this way the vast majority
of equity option structures that are used between wholesale market
counterparties can be represented in FpML.
The product architecture draws heavily on ISDA's 1996
definitions for equity derivatives as updated by the emerging 2002
definitions. Wherever possible the terminology and practice of the ISDA
definitions has been adopted to ensure consistency between traditional and
FpML contract representations.
The underlyer of an equity option may be either a single underlyer, or basket, specified using
the underlyer component specified below
The strike is expressed either as a price (strikePrice)
or as a percentage (strikePercentage) of the forward starting spot
price. An optional currency element caters
for the case where the strike price is expressed as a monetary amount, rather
than as a level.
The numberOfOptions
element specifies the number of options in the option transaction. The
optionEntitlement element specifies the number of
shares per option. The number of options, strike price and notional are
linked by the equation:
notional amount = number of options x
option entitlement x strike price
Provided that two of notional amount, number of options
and option entitlement are specified, then the third may be omitted.
spotPrice is the price per share, index or basket observed on the trade or effective
date. It is only used for forward starting options.
The exercise provisions for the option are specified in
the equityExercise component. American,
European and (new in FpML 4.0) Bermudan styles are all catered for. The
equityExercise component is described in more
detail below.
Quanto options are handled using the new FXFeature
component, which is described below.
Where necessary many other non-vanilla features are
specified in the optional equityOptionFeatures component, which is also new
in FpML 4.0. This component is described in more detail below.
The equityPremium
component specifies the amount and timing of the premium payment that is made
for the equity option. It is described in more detail below.
Where the underlying is shares, the extraordinaryEvents
component specifies marketevents affecting the issuer of those shares that may require the terms of the
transaction to be adjusted. The methodOfAdjustment component specifies how
adjustments will be made to the contract should one or more of the
extraordinary events occur.
The underlyer component specifies the asset(s) on which the option is
granted, which can be either on either a singleUnderlyer
or basket, and consist of equity, index, or convertible bond components, or some combination of these
The description element is used to provide a free-form
text description of the asset, whereas instrumentId contains a short-form, unique
identifier (e.g. ISIN, CUSIP) for the asset. At least one instrumentId
must be present.
The exchangeId element
contains a short form unique identifier for an exchange. If omitted then the
exchange shall be the primary exchange on which the underlying is listed. The
relatedExchangeId element contains a short
form unique identifier for a related exchange. If omitted then the exchange
shall be the primary exchange on which listed futures and options on the
underlying are listed.
The clearanceSystem
element contains the identity of the clearance system to be used. If omitted,
the principal clearance system customarily used for settling trades in the
relevant underlying shall be assumed.
FpML 4.0 supports three styles of equity option: European,
American and Bermudan. For consistency of representation with interest rate
derivatives each of these styles is represented using its own component. Each
of these components is described more fully below. The
automaticExerciseApplicable element contains a
boolean value to indicate whether or not the option (or any remaining portion
of the option, if multiple exercise is permitted) is exercised automatically
if it expires in the money.
The equityValuation
component specifies the date and time on which the option is valued. The
element valuationTimeType enables the
valuation time to be expressed as relative to some other event, such as the
close of business for the exchange. Alternatively if its value is "Specific"
then the element valuationTime is used to
specify an explicit time of day.
The futuresPriceValuationApplicable element contains a
boolean value to indicate whether or not the official settlement price as
announced by the related exchange is applicable, in accordance with the ISDA
2002 definitions.
The settlementDate
component specifies when the option is to be settled relative to the
valuation date. If the settlement date is not specified explicitly then
settlement will take place on the valuation date. The settlementType component is used to specify whether
the option is settled in cash or physically.
The settlementPriceSource
element specifes the source from which the settlement price is to be
obtained, e.g. a Reuters page, Prezzo di Riferimento, etc.
The failureToDeliverApplicable element is used where
the underlying is shares and the transaction is to be physically settled. The
element contains a boolean value that, if "true", then a failure to deliver
the shares on the settlement date shall not be an event of default for the
purposes of the master agreement.
The sub-components of the equityEuropeanExercise component specify the date
and time when the option will expire. The element equityExpirationTimeType enables the expiration
time to be expressed as relative to some other event, such as the close of
business for the exchange. Alternatively if its value is "Specific" then the
element equityExerciseTime is used to specify
an explicit time of day.
The commencementDate and expirationDate are used to specify the period
during which the option may be exercised (more than once if permitted by the
equityMultipleExercise component). The option
may be exercised on any business day in this period up to the latest time
specified for exercise. The element equityExpirationTimeType enables the expiration
time to be expressed as relative to some other event, such as the close of
business for the exchange. Alternatively if its value is "Specific" then the
element equityExerciseTime is used to specify an explicit time of day.
The element latestExerciseTimeType enables the latest exercise
time to be expressed as relative to some other event, such as the close of
business for the exchange. Alternatively if its value is "Specific" then the
element latestExerciseTime is used to specify an explicit time of day.
The commencementDate and
expirationDate components are used to specify
the period during which the option may be exercised (more than once if
permitted by the equityMultipleExercise
component). The option may be exercised on any of the days in the list
bermudanExerciseDates up to the latest time specified for exercise. The
element equityExpirationTimeType enables the expiration
time to be expressed as relative to some other event, such as the close of
business for the exchange. Alternatively if its value is "Specific" then the
element equityExerciseTime is used to specify
an explicit time of day.
The element latestExerciseTimeType enables the latest exercise
time to be expressed as relative to some other event, such as the close of
business for the exchange. Alternatively if its value is "Specific" then the
element latestExerciseTime is used to specify
an explicit time of day.
The type of FX feature is specified in the element FXFeatureType, and may be
either Quanto or Composite
Quanto - where two currencies are involved. To adjust the investor's base currency
protection on an underlying position which varies in value in the non-base currency.
Composite - where multiple currencies can be involved. An option is struck on a
foreign underlying at a value of the underlying in the investor's base
currency. The payout is based on the investor's base currency at exercise.
The FX rate may be specified as an explicit rate using FXRate, or by using the
FXSource component to specify the source from which the FX rate is to be obtained.
Three types of option features are catered for in FpML
4.0: asians, barriers and knocks. All of these are path-dependent options.
Asian features are described below. Barriers may be caps or floors; knocks
may be knock-ins or knock-outs - these share a common architecture that is
described below.
A binary option (also known as a digital option) is a
special case of a barrier where the payout is specified to be a fixed amount
rather than a percentage of the value of the underlying on the date that the
option is triggered.
An asian option is one in which an average price is used
to derive the strike price ("averaging in") or the expiration price
("averaging out") or both. The type of averaging is specified in the
averagingInOut element.
The period over which the averaging is calculated is
specified in the component averagingPeriodIn
or averagingPeriodOut as appropriate. Both
components have the same structure. The period is specified either as a
calculation, using one or more schedule
components (which permits specifications such as every Friday from and
including 24 May 2002 to and including 22 November 2002), and/or as a
list of explicit dates and times, using the
averagingDateTimes component. It is permissible to
use the list of dates and times to specify averaging points that are
additional to those derived from the calculation rule specified in
schedule components. In the event that any of the
dates is not a business day then it is assumed that it will be rolled forward
to the next business day in accordance with ISDA convention.
The marketDisruption
element specifies the action to be taken if it is not possible to obtain a
price on one of the days used for averaging.
A barrier option is one in which, if the option expires in
the money, an additional payment will occur. With a barrier cap the
additional payment will be made if the trigger level is approached from
below, whereas with a barrier floor the additional payment will be made if
the trigger level is approached from above.
Knock options are of two types. A knock-in option does not
come into effect until the trigger level has been reached, if it is never
reached then the option expires worthless. Conversely, a knock-out option
expires immediately the trigger level is reached.
A common structure is used to specify barrier caps,
barrier floor, knock-ins and knock-outs. The diagram shows the
barrierCap structure.
The dates on which the underlying is valued to test for
the occurrence of the trigger event are either expressed in one or more
schedule components and/or as a list of explicit
dates, using the triggerDates component. It
is permissible to use the list of dates to specify trigger dates that are
additional to those derived from the calculation rule specified in
schedule components. In the event that any of the
dates is not a business day then it is assumed that it will be rolled forward
to the next business day in accordance with ISDA convention.
The trigger component
specifies that the trigger event either as a
level or as a levelPercentage
(of the strike).
The optional featurePayment component specifies a payment to be
made if the trigger event occurs. The payment date can be expressed either as
an explicit date or as relative to some other date, such as the trigger date
or the contractual expiry date.
The equityPremium
component specifies the amount and timing of the premium payment that is made
for the equity option. payerPartyReference
and receiverPartyReference are pointer style
references to party components that specify
the payer and receiver of the premium respectively.
In FpML 4.0 the premium amount can be expressed in a
number of ways: as a monetary amount (paymentAmount), as a price per option or as a
percentage of the notional - if more than one method is used then they must
be mutually consistent. There are circumstances in which no premium would be
specified, for example if the trade formed part of a put/call combo
structure.
The swapPremium element
holds a boolean value that, if "true" specifies that the premium is to be
paid in the style of payments under an interest rate swap contract.
When a date specified in an equity option contract falls
on a non-business day then it may be necessary to adjust it to be a business
day. At the time the contract is agreed it is not always possible to
determine whether or not a particular date in the future will be a business
day.
The meaning of "business day" varies according to the
context in which it is used. When the context is the payments of monetary
amounts then the rules for adjustment according to currency business days
apply, and the equity option product architecture uses the
same AdjustableOrRelativeDate
component ( or derivations ) as the interest rate and foreign exchange products.
However, when the context is the valuation or settlement
of equities or equity indices then the term "business day" means "exchange
business day". In this case the equity option product architecture specifies
the use of unadjusted dates with the adjustment rules being implicitly
inherited from the ISDA definitions.
FpML 4.0 Equity Derivative Swaps Product Architecture extends the product coverage of FpML to include the equity swap.
This document provides an in-depth review of the technical architecture of the FpML 4.0 Equity Swap schema. The current limitations
of this schema, which will be addressed through a next release, are described through the following paragraphs.
Like all other derivative products supported by FpML, the type used to represent the equity swap, EquitySwap, is defined as
an extension of the Product type and the corresponding equitySwap element belongs to the product substitution group.
The scope of this FpML representation for equity swaps is to capture the following types of swaps:
Single stock swaps as well as basket swaps;
Swaps that have a different types of underlying assets (equity, index, mutual funds, exchange-traded funds, convertible bond,
futures), or a combination of these;
2-legged swaps with a combination of an equity leg and a funding leg, as well as swaps that either have only one leg (e.g.
fully funded swap) or multiple equity legs;
Swaps that have specific adjustment conditions, such as execution swaps or portfolio rebalancing swaps;
Zero-strike swaps, which do not have an interest rate component but rather involve the exchange of principal cashflows.
This current version of the FpML representation for the equity swap is focused on representing the economic description of
the swap. The Extraordinary Events terms will be incorporated at a later point in time, and will take into consideration
the recent release of the 2002 ISDA Definitions for Equity Derivatives. The trigger and the stubs will also be incorporated
through a later release.
The FpML representation of the equity swap relies on 5 key structures that are presented in the Figure 1 below:
The equityLeg component specifies the equity amounts of the swap. There can be one or several equity legs.
The interestLeg component defines the financing leg of the swap. The possibility is provided for having swaps that do not have an interest
leg (case of an outperformance swap where 2 equity underlyers are swapped, or a zero-strike swap where there is no financing
component).
The PrincipalExchangeFeatures is an optional component that describes the case where principal cashflows are exchanged between the parties to the trade.
Similarly to the interest rate swap structure, the equitySwapAdditionalPayment component supports the other types of payments involving the parties to the trade, such as fees.
Finally, the equitySwapEarlyTermination component specifies, for one or for both the parties to the trade, the date from which it can early terminate it.
The following developments detail each of these five structures of the equity leg of the swap.
The identification of the payer and receiver party of the equity leg is done similarly to the other types of swaps, through
the payerPartyReference and receiverPartyReference data elements.
The effective date and the termination date are similarly defined for both the interest and equity leg of the trade. Each of these dates can be specified in reference
to either a date defined somewhere else in the document (using the relativeDate subcomponent) or as a specific date (using the adjustableDate subcomponent).
The underlyer component provides a detailed description of the characteristic of the underlying asset(s). Seven types of asset classes
have been included as part of this release:
The equity:
The index:
The mutual fund:
The exchange-traded fund:
The future contract:
The convertible bond:
The bond:
The description of the attributes that are common across these various asset classes is done through the underlyingAsset component.abstract
that defines the generic elements. This component is also used for specifying the underlying equity of a convertible bond:
This underlyingAsset component is used through two different structures, depending upon whether the swap has only one single
underlyer or whether it has multiple underlying assets:
In the case of a single underlyer, the singleUnderlyer component specifies the number of open units, the description of the underlyer through the underlyingAsset substitution group and the dividend payout ratio (which is defined through the underlyer component rather than the return
component for reasons that are related to the basket, and that are explained below).
The basket component is to be applied in the case where there are several underlyers, which are then specifically described
through the basketConstituents component. This basket component is structured as follows: an identification of the number of basket units (typically, one)
and a description of each of the underlyer constituents.
Each of these basket constituents is specified through an asset description, a constituent weight (either in absolute or relative
terms) and a dividend payout ratio. The ConstituentWeight is an optional component, considering that some types of swaps do not have a relative weight associated to each their components.
The dividend payout ratio has been associated with the description of the underlyer rather than included in the definition of the return in order to address the case where a different payout ratio is be associated with the respective components of a basket swap.
The valuation component describes the conditions that govern the valuation of the swap, with the definition of both the initial reference
price and the later valuations and payment dates. The determination of whether notional resets are applicable to the swap
is also part of this composent.
The valuation component has four main internal components: one that describes the initial price (initialPrice), one that describes the interim valuation price, when applicable (valuationPriceInterim), one that describes the final valuation price (valuationPriceFinal) and one that describes the equity payment dates (equityPaymentDates).
These four components are based on three main structures: a component that describe the price, a component that specifies
the valuation date(s) and a component that describes the payment date(s):
Three possible ways of defining the price of the underlyer are available: as an actual price and currency (typically for the initial price), in reference to an amount
defined somewhere else in the document using the amountRelativeTo element (for the initial price of basket swaps, for example), or using the determinationMethod component (typically, for the interim valuation price and the final price). Commissions that be associated with each of
these three alternative definitions. In the case of a Composite FX swap, the possibility is provided, through the fxConversion component, to explicitly define the FX rate associated supporting the initial price that is expressed in the reference currency
of the swap.
The interim valuation dates can be described in three possible ways: as an actual schedule of dates (which is the most frequent case), in relation to
dates defined somewhere else in the document (a valuation date could, for example, be defined as a function of the equity
payment date), or through a periodic rule (similarly to the fixed income practice). The figure 17 shows these three alternative
ways for defingin the interim valuation dates. The adjustableDates component provides the ability to define the schedule of dates. The relativeDateSequence supports the definition of dates in relation to other dates, by also providing the ability to specify several offset dates
in order to address the complexity caused by differences between currency and exchange holidays. The periodicDates component supports the definition of periodic dates.
The figures 18 and 19 detail the relativeDateSequence structure, with this ability to specifies an offset sequence. For example, the equity valuation date could be defined as
being 2 exchange business (sequence 1) and 1 currency business day (sequence 2) before the equity payment date, addressing
the issue of potentially having a currency holiday that is a working day for the local exchange.
Figure 20 presents the structure of the periodicDates component, which supports the definition of periodic dates:
The equityPaymentDates component specifies both the interim and final payment dates, which can also be defined as a schedule of dates or in relation
to dates defined somewhere else in the document (typically, the valuation dates). An identifyer is associated with this equityPaymentDates
component, that is used to refer to all these various dates for specifying the dividend payment date when such dividends will
be paid on the equity payment date.
The equitySwapNotional component specifies the notional of each of the legs of the swap (it is indeed also present in the interest leg of the trade).
Similarly to the price of the underlyer, three possible ways of defining this notional are available:
By specifying an actual amount and currency.
By referencing an amount specified somewhere else in the document. This is typically the case of the interest leg of the
swap, which notional refers to the one determined through the equity leg.
By specifying a method, using the determinationMethod component This is typically useful for forward swaps, which notional is not known on trade date.
The main purpose of the equityAmount component is to specify the method that determines the equity amount to be paid/received on each of the equity payment dates.
Its role however goes quite beyond this, as it also:
Specifies whether the swap will cash settle of physically settle.
Specifies the settlement currency of the equity leg of the swap (either specifically or by reference to the currency defined
through the fxTerms component, when applicable).
In relation to its role for defining the equity amount of the swap, the equityAmount component provides the ability to either refer to the standard ISDA Definition or to a method defined somewhere else in the
document, using the referenceAmount component, or describe a very specific formula. In this latter case, a flexible structure is provided:
The encodedDescription component provides the ability to encode an image that describes the payout formula, using a base64Binary structure
The formula component provides a flexible structure for describing the payout formula, using the combination of the formulaDescription component that provides a literary description of the payout formula, the math container that uses the xsd:any XML structure to hold any type of formula description, and the formulaComponent element that describes the various components of the formula.
In association with this structure, the calculationDates component provides an optional reference to calculation dates (if, for example, observation dates are needed).
The return component encapsulates the information that defines the dividend to be paid to the receiver of the equity amounts, with the
exception of the dividend payout ratio, which is specified through the underlyer component.
The main structure of this return component is the dividendConditions, which describes the various conditions applicable to the dividend, including whether and how interests will be accrued if
they are paid after the dividend pay date; indeed, the returnType is an element that simply specifies whether the swap is a total, dividend or price return contract.
The figure 27 presents this dividendConditions component, which various subelements are the following:
dividendReinvestment, as a Boolean data element that determines whether the dividend will be reinvested into the equity notional or not;
dividendEntitlement, to indicate when the counterparty is entitled to the dividend;
dividendPaymentDate, to specify when the dividend will be paid, these possible dates being defined either as restricted attributes (when being
a dividend date), in reference to a date defined somewhere else in the document (typically, the equity payment date) or as
a specific date;
dividendPeriodEffectiveDate and dividendPeriodEndDate, to indicate when the swap is considered as active from the perspective of dividend processing
and when such period ends;
dividendFxTriggerDate, to specify the date on which the FX rate will be considered in the case of a Composite FX swap;
interestAccruals, to define how interests will be accrued on the dividend when this latter is paid some period of time after the dividend
payment date.
The notionalAdjustments component specifies whether the adjustment to the equity notional of the swap will obey to certain specific terms. These
terms can be, according to the current industry practice, twofold: execution and portfolio rebalancing.
The fxTerms component specifies the FX conversion terms that can be associated with the swap, that may be either Quanto or Composite
FX. Both these components include a referenceCurrency element, which purpose is to explicitly state the reference currency of the swap.
The quanto component includes an explicit reference to a rate, through the quantoRate element. One or several rates can be define, in order to address the case where a basket swap is composed of several underlyers
that are listed in different currencies.
The compositeFx component provides the framework for defining a currency rate at some point in the future. This can be done either by defining
a generic method using the determinationMethod component (for example, when it is agreed that the exchange rate will be determined "in good faith by the Calculation Agent")
or by specifying the information source and fixing time and date reference that will be used for defining this exchange rate,
using the fxDetermination component.
The interest leg of the swap leverages the components defined for the interest rate swaps at a more granular level than the swapStream. This is due to the difference in market practices between the equity and fixed income products. The industry practice
for the equity swaps consists in defining a schedule of actual dates for the equity valuation, while most of other swap dates
are defined in reference to this schedule; the practice in place in the interest rate area consists, on the other hand, in
defining periodic rules. As a result, the swapStream features are largely focused on defining such periodicity rules along
with the appropriate calendar exceptions, and do not provide the possibility for defining a set of actual dates (if we except
through the firstPeriodStartDate, the firstRegularPeriodStartDate and the lastRegularPeriodEndDate) and references to these.
Instead of leveraging the whole swapStream component, the interest leg of the equity swap leverages then components at a more
granular level, such as the resetFrequency component, the interestCalculation component or the calculationPeriodDatesReference element.
As a result, the interest leg of the equity swap has 4 categories of components, that are presented in the figure 32 and detailed
thereafter:
The identification of the payer and receiver party of the equity leg is done similarly than for the equity leg of the swap,
through the payerPartyReference and receiverPartyReference data elements.
The notional amount is defined through the same structure than for equity leg of the swap: the equitySwapNotional component; in practice, this component is most often used for referencing the notional amount that is defined as part of
the equity leg.
The interest amount is defined in the same way than the equity amount: using the LegAmount complex type. Similarly to the equityAmount, it specifies the following elements:
Whether the swap will cash settle of physically settle.
The settlement currency of the interest leg of the swap.
The interest amount of the swap, either by reference to the standard ISDA Definition or by describing a very specific formula.
The interestCalculation component specifies the interest rate reference of the swap (by referring either to a fixed interest rate or to a floating
reference rate) and the day count fraction standard to be applied. As indicated in the introduction to the interest leg,
this structure has been developed by leveraging the components defined for the interest rate swap schema.
Some types of equity swaps do not have an interest leg. Their economic structure relies instead in the exchange of the principal
of the swap between the parties. The purpose of the PrincipalExchangeFeatures component is to accommodate this type of swaps.
This component extends the design developed for the interest rate swaps through the principalExchangescomponent by adding the PrincipalExchangeDescriptions component which has the following features:
It specifies the payer and receiver party references;
The date of each of the principal exchanges can be defined either as an actual date (using the adjustableDatecomponent) or in relation to a date defined somewhere else in the document (through the relativeDate component);
The principal exchange amount can be defined in three possible ways: (i) By pointing to an amount defined elsewhere in the
swap document, through the use of the amountRelativeTo element; (ii) By using the determinationMethod element, that describes a method according to which an amount is determined; (iii) By using the principalAmount component, which allows to explicitly determine an actual amount.
Similarly to the principal exchange, the EquitySwapAdditionalPayment complex type extends the design developed for the interest rate swaps by providing the ability to define dates in relation
to other dates, as well as to specify the calculation logic that supports certain types of fees.
This structure leverages features that are also used through other components:
The payer and receiver parties are specified similarly than for the swap legs and the principal exchange, through the payerPartyReference and receiverPartyReference data elements.
The additionalPaymentAmount component provides the flexibility to define an actual amount (through the paymentAmount component) and/or to describe the methodology for determining such amount, leveraging the fomula component developed for the LegAmount complex type.
Similarly to the PrincipalExchangeFeatures component, the date of each of the additional payments can be defined either as actual dates or in relation to dates defined
somewhere else in the document, through respectively the adjustableDate and the relativeDate components.
The purpose of the equitySwapEarlyTermination component is to specify the date from which each of the parties to the trade may have the right to terminate it early. Figure
39 presents the structure of this component:
Description: All global elements except for the FpML root element and members of substitution groups have been eliminated.
All types referencing global elements now declare local elements of the same name.
Rationale: eliminate cross-asset name clashes, reduce documentation size.
Refers to: all schema files, fpml-4-0-schemeDefinitions.
Description: Convert many schemes to enumerations. Schemes and the corresponding simple types have been converted to enumeration
types with the same name plus the 'Enum' suffix. The corresponding scheme default attributes have been removed from the FpML
root element.
Rationale: Provide schema-based validation. Simplify document processing.
Refers to: FpML element in fpml-4-0-main.xsd, plus local scheme type definitions throughout the document.
Description: Eliminate scheme default attributes in the FpML root element for all schemes. For certain relatively standard
schemes (such as the currency scheme), provide default attribute values in the schema itself. For non-defaulted scheme attributes,
make them required.
Rationale: Improve maintainability and readability of the FpML root element. Simplify processing of FpML documents. Highlight
deviations from standard FpML practice.
Extensive changes to examples to correspond to the global changes above. Some examples of changes include:
eliminated scheme default attributes from the FpML root element.
changed element text for enumerations, and updated to UpperCamelCase except for schemes present since FpML 1.0/2.0. Heavily
affected FX examples, and also EQS examples
eliminated some scheme attributes were no longer required because of the change to enumerations. This heavily affected the
EQS examples
added some scheme attributes where required by the elimination of scheme defaults
Here is some more detail on the changes
IRD: changed examples to DataDocuments
FX: changed all FX Enumerations to CamelCase - affected enums.xsd, most examples file
made tradeIdScheme optional
made productTypeScheme available again on productType
added RollConvention = NONE for FX ex#20
MSG: made messageIdScheme on messageId optional (for messaging examples)
EQS: corrected the use of DayType, eliminated scheme
EQS: changed businessDayConvention of 'Not Applicable' to 'NONE'
EQS: corrected the use of dateRelativeTo, added 'TradeDate' as element content
EQS: corrected the use of returnType, eliminated scheme
EQS: corrected the use of dividendEntitlement, eliminated scheme
EQS: corrected the use of notionalAdustments, eliminated scheme
EQS: corrected the use of commissionDenomination, eliminated scheme
EQS: corrected the use of quoteBasis, eliminated scheme
EQS: corrected the use of dividendDateReference, eliminated scheme
CD: changed referenceEntity to reflect new structure of LegalEntity
CD ex#3, etc: changed primaryObligor for reflect new Legal Entity structure
Description: The masterAgreement element of the complex type Documentation is now optional.
Rationale: Allows representation of a Master Confirmation Agreement in the cases where the counterparties have not yet signed
a Master Agreement or the Master Agreement is referenced in the Master Confirmation Agreement.
In the discussion of coding schemes, FpML dates were described as having "at least 4 digits" and as being in the range 0000-9999.
This is inconsistent. This was corrected to "having exactly 4 digits".
Description: The following adjustments were made to the equity swaps schema:
The spelling of the legIdentifier attribute associated with the equityLeg and the interestLeg has been corrected (the previous
value was legIdentifyer).
Two changes have been made to the equitySwapEarlyTermination component. The first one has been to replace the element StartingDate
with startingDate. The second change has consisted in replacing the unbounded sequence node with an unbounded equitySwapEarlyTermination,
in order to provide more clarity in the schema. This also caused slight changes to EQS examples #1 and #2.
Description: Several schemes were modified to support changes in FpML 4.0 Credit Derivatives:
additionalTermScheme: New scheme associated with the AdditionalTerm type.
contractualSupplementScheme: Added codes to represent the May 2003
supplement and the Monoline Insurer Provisions. All credit derivatives related code prefixes are now of the form ISDAYYYYCredit
where YYYY is the four digit year the supplement was adopted. Changed URI to include "scheme" for consistency with other
URIs.
entityIdScheme: New scheme associated with the LegalEntity type.
entityNameScheme: New scheme associated with the LegalEntity type.
instrumentIdScheme: Added alternate URI for RED pair codes.
masterAgreementTypeScheme: Added codes to support the 2003 Credit Derivatives Master Confirm Agreement.
referenceEntityScheme: Deleted.
masterConfirmationTypeScheme: Changed URI to include "/spec". Changed spec to introduce "MasterConfirmationType" ComplexType,
with a scheme attribute defaulted to the appropriate value.
restructuringScheme: Changed URI to include "/spec", and updated example #7.
Several changes were introduced to the FpML root element and the MessageRejected type to better support validation errors.
Changes included:
optional validationScheme attribute added to the FpML root element.
optional validationScheme attribute has been added to the NotificationMessage type.
optional validationScheme attribute has been added to the MessageRejected type.
The Reason type (used in MessageRejected) has been extended to include more information in the location element, a validationRuleId,
and additionalData.
Description: Feedback has been received that there is a need to support the ability to specify an optional separate fixing
date offset for the initial fixing. This will involve adding an optional element, initialFixingDate, into ResetDates. This
change is backwardly compatible.
Detail: Change ResetDates type definition by adding the optional element initialFixingDate, of type RelativeDateOffset
Description: Feedback has been received that the cashflow support within FpML would be improved by allowing the inclusion
optionally of the unadjusted cashflow dates.
Correction: Add unadjusted cashflows dates within each cashflow component. The following changes are required:
Detail: Change CalculationPeriod type definition (add optional elements: unadjustedStartDate, unadjustedEndDate, calculationPeriodNumberOfDays
and change occurrence rule for elements: adjustedStartDate and adjustedEndDate to zero or one)
Description: Feedback has been received that the cashflow support within FpML would be improved by allowing the inclusion
optionally of the unadjusted cashflow dates.
Correction: Add unadjusted payment dates within each cashflow component. The following changes are required:
Change PaymentCalculationPeriod type definition (add optional element: unadjustedPaymentDate and change occurrence rule for
element: adjustedPaymentDate to zero or one)
Description: Feedback has been received that the cashflow support within FpML would be improved by allowing the inclusion
optionally of the unadjusted cashflow dates.
Correction: Add unadjusted cashflows dates within each cashflow component. The following changes are required:
Change PrincipalExchange type definition (add optional element: unadjustedPrincipalExchangeDate and change occurrence rule
for element: adjustedPrincipalExchangeDate to zero or one)
Description: Feedback has been received that a resetDate element is required for FX Linked Notionals.
Correction: Add element resetDate to FxLinkedNotionalAmount.
Change FxLinkedNotionalAmount type definition (add optional element: resetDate and change occurrence rule for element: adjustedFxSpotFixingDate
to zero or one)
Correction: Change description to: "The number of days from the adjusted effective / start date to the adjusted termination
/ end date calculated in accordance with the applicable day count fraction."





















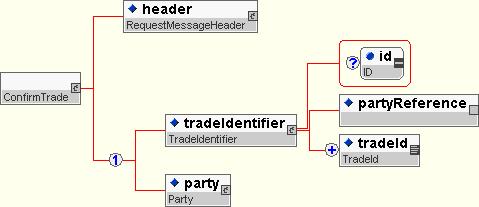






























































































 In the
In the 










