4.1 Validation Rules
This section defines the business validation rules architecture that was established by the Validation Working Group. It contains introductory and background information about the purpose of validation, a guide to how to make use of the documents published by the Validation Working Group, and serves as a reference point for implementers.
The main documents produced by the Validation Working Group is the set of validation rules, expressed in English:
- Equity Derivative Rules: Business constraints for EQD definitions.
- Interest Rate Derivative Rules: Business constraints for IRD definitions.
- Credit Derivatives Rules: Business constraints for CD definitions.
- FX Rules: Business constraints for FX definitions.
- Syndicated Loans Rules: Business constraints for Syndicated Loans definitions.
- Pricing and Risk Rules: Business constraints for Pricing and Risk definitions.
- Business Process Rules: Business constraints for Business Process messages.
- Shared Elements Rules: Supplementary business constraints in addition to the specific assets.
- ID / IDREF Rules: Business constraints for ID / IDREF relationships.
- Test Cases (zip file): Download file containing normative test cases.
The validation rules follow the principles and guidelines defined in the Validation Rule Specifications section.
Previous versions of the validation rules, expressed in English:
- Validation Rules 4.1 - July 19, 2004: http://www.fpml.org/spec/2004/FpML-4-1/validation/
- Validation Rules 4.0 - April 2, 2004: http://www.fpml.org/2003/FpML-4-0/validation/
The Validation Working Group's charter includes a mandate to formalize the validation rules from their plain English representation to a suitable implementation language. The purpose of this decision was to disambiguate the English language representation, to serve as a point of reference for implementers looking for clarification, and to validate the test cases produced by the working group. Reference implementations play an important part in providing quality guarantees to the working group and it is hope that their publication will be useful to implementers.
The reference implementations are non-normative and should not be considered publications of the Validation Working Group. Instead, they are contributions provided by members of the working group or other implementers.
Although the working group does not have the means to provide official certification, it expects implementers to demonstrate that they produce the correct results - valid or invalid - for the normative test cases of each implemented rule. There is no requirement to implement all rules, but reference implementations will state clearly which rules are implemented by publishing a list of rule identifiers.
4.2.1 Java and C#
| Provider |

|
| Implementation Language | Java and C# |
| Implemented Rules | All published FpML rules (plus adjustments for FpML 1.0, 2.0 and 3.0); Additional rules for datatypes (in DTD documents FpML 1.0, 2.0 and 3.0); Additonal rules for schemes (all FpML releases) |
| Browse | N/A |
| Further Information | http://www.handcoded.com |
4.2.2 Java/XPath
| Provider |

|
| Implementation Language | Xpath/Java |
| Implemented Rules | All versions, All rules |
| Browse | FpML Reference Implementation |
| Further Information | http://www.iona.com/products/artix/standards_libraries.htm |
4.2.3 CLiX
| Provider |

|
| Implementation Language | CLiX / Java |
| Implemented Rules | http://www.fpml.org/2003/FpML-4-0/validation/2004-04-02: All rules |
| Browse | FpML Reference Implementation |
| Further Information | http://www.messageautomation.com |
4.2.4 XQuery
| Provider |
|
| Implementation Language | XQuery |
| Implemented Rules | All rules, version 4.5+ |
| Browse | N/A |
| Further Information | FpML Reference Implementation |
The Validation Working Group also publishes a set of test cases with each rule set release (available above). For each rule, a number of valid examples and a number of invalid counter-examples are given. The test cases for a release will have been validated both manually and against at least one reference implementation to check that they are correct. The test cases have the following properties:
- All test cases are valid against the schema
- Every valid test case is valid against all rules (business valid), but is guaranteed to carry the information that the particular rule it is designed to test against makes use of.
- Every invalid test case for a rule is guaranteed to violate the rule, but may in addition violate other rules.
- Each invalid test case must state which instance of the context is invalid. For example an invalid document with more than one matching context must state which contexts are invalid, and the other contexts must be valid.
- There is no guarantee of completeness. The test cases are designed for disambiguation and test the most common violations, they are not an exhaustive set of boundary cases.
This document should be useful to:
- Architects that need to consider the impact of semantic validation on the overall workflow or processing pipeline. Relevant section: Validation Architecture Concepts
- Implementers of FpML that need to understand how to make use of the validation rules in implementations. Relevant section: Validation Rules and Reference Implementations
- Analysts or other interested parties who wish to use the validation rules to further their understanding of FpML. Relevant section: Background
FpML has been designed as a very rich language, with a large amount of optionality in its element and attribute definitions. This richness, which arises from the complexity of the information that FpML is designed to carry, has made it easier for implementers to fit FpML into existing architectures, and has facilitated the reuse of common element types across different asset classes.
Partly due to this flexibility, and partly due to the rich structure of FpML, it is unrealistic to assume that a schema-validated FpML document is necessarily correct in a business sense. The Validation Working Group was established early in 2003 to consider the implications of this problem and breaks down the correctness of an FpML document into three parts:
- Well-formed XML: The document meets the basic XML well-formedness constraints defined by W3C.
- Schema Compliance: The document is valid against the Schema that the document references.
- Business Rules Compliance: The document is valid against the validation rules published by the Validation Working Group.
It is useful to consider some simple example to illustrate the different levels of validity. The following is a fragment of a well-formed FpML document, but violates the schema due to an invalid start date:
<calculationPeriodDates>
<effectiveDate>
<unadjustedDate>xxxx-xx-xx</unadjustedDate>
..
</effectiveDate>
<terminationDate>
<unadjustedDate>2004-02-29</unadjustedDate>
..
</terminationDate>
..
</calculationPeriodDates>
The following version of the fragment is syntactically valid, because the contents of the effective date now match the schema definition of a valid date.
<calculationPeriodDates>
<effectiveDate>
<unadjustedDate>2004-08-29</unadjustedDate>
..
</effectiveDate>
<terminationDate>
<unadjustedDate>2004-02-29</unadjustedDate>
..
</terminationDate>
..
</calculationPeriodDates>
The fragment of FpML inserted above is however not semantically valid, because the effective date of the trade precedes the termination date. As a consequence, the trade is not meaningful and in fact violates one of the validation rules for IRD interest rate streams. Many other types of constraints will not be validated by the schema, which is designed to designate structure, not semantics:
- Constraints between the contents of multiple elements, like as in example given above
- Relationships between elements in distant parts of the document
- Complex data type operations that require processing, for example checking cash flows against the parametric representation
- Reference data validity, or other checks against external documents or databases
The validation working group has considered these problems and their implications, and has attempted to address a number of questions. How do we extract the knowledge about what constitutes a correct trade from business experts? What, if any, guarantees will we give that our work is complete? What is the normative status of the validation rules? How can parties override or tailor the rule set? What infrastructure support is necessary in the FpML architecture to enable rule-based checking? What support is necessary in the new messaging framework? The answers to these questions are addressed in the remainder of this section.
This section defines the guiding principles and requirements for how rules should be defined and written. The Validation Working Group’s desire is to define a set of guidelines, which when followed produce a set of rules which conforms to an agreed standard of layout and content, with the intention that the rules are coherent, complete and well-defined; and therefore usable by practitioners.
4.6.1 General Principles and Guidelines
Validation rules should be written in a stylized plain English which is both precise and complete, but not necessarily formal:
- The target audience is business analysts and programmers familiar with OTC derivatives
- The rule definitions must be precise
- Rules must be written in the terms of an infoset. At present the only suitable infoset is XDM *
- For each context of a rule, the rule must evaluate to a single XML schema Boolean value +
- The definition of each English term should correspond to an XPath 2 expression. NB all other terms or tests must be defined using terms already defined or existing XPath 2 expressions (cf. http://www.w3.org/TR/xpath20). Any reference to XPath is to XPath 2.
* XML infoset does not contain schema information; PVSI contains gaps and impossible scenarios when used for rules, and therefore is unsuitable; this is why the W3C created the XDM infoset. NB model groups do not appear in XDM and therefore cannot be defined in the rule (they are also context free)
+ other cases would result in ambiguity, e.g. an optional Boolean value or more than one Boolean value (multiplicity)
4.6.2 Mathematical Notation
There is a list of approved mathematical symbols which must be used, in the formal description, instead of their natural language equivalents. This list contains the commonly understood mathematical symbols. Only the symbols on the approved list may be used in the formal description. Their advantage is their terseness and readability compared to natural language.
To avoid confusion with XPath definitions, each symbol must be separated for other words with a space. Otherwise for example the division symbol and the XPath symbol would be confusable.
The approved mathematical symbols are:
| eq | equality (XPath value comparison operator) |
| ne | inequality (XPath value comparison operator) |
| lt and gt | is less/greater than (XPath value comparison operator) |
| le and ge | is less/greater than or equal (XPath value comparison operator) |
| + | addition (plus) |
| - | substraction (minus) |
| * | multiplication |
| / | division |
| () | precedence grouping |
XPath value comparison operators (eq, ne, lt, le, gt, ge) are defined in the XPath specification.
4.6.3 Rule Definition and Layout
To ensure consistency and improve readability rules should be defined using the following syntax (the notation is expressed using EBNF):
| Rule | ::= | RuleIdExpr Contexts RuleDef Tests |
| RuleIdExpr | ::= | RuleId “(” “Mandatory” | “Warning” “)” |
| RuleId | ::= | ProductType “-” Digits |
| ProductType | ::= | One of the product type or shared |
| Digits | ::= | [0-9]+ |
| Contexts | ::= | Context (“,” Context)* |
| Context | ::= | “Context:” TypeName (ContextConds) |
| ContextConds | ::= | ContextCond (ContextCond)* |
| ContextCond | ::= | “[”ConditionExpr | ValCondition “]” |
| ConditionExpr | ::= | Precise definition of the rule expressed in English using defined terms |
| ValCondition | ::= | Reference to a global validation condition (ref) expressed in English |
| TypeName | ::= | XML Schema Type Name (complex type) |
| RuleDefEnglish | ::= | English definition of the rule expressed in natural language. This description may include business reasons or examples. |
| RuleDefFormal | ::= | Formal definition of the rule expressed in XPath and defined terms |
| Tests | ::= | “Test Cases:” Valid (Valid)* Invalid (Invalid)* |
| Valid | ::= | “[“ DocLink “]” |
| Invalid | ::= | “[“ DocLink “]” |
| DocLink | ::= | Link to a test case document |
- rule identifier must be unique and as appropriate the product type they apply to should prefix any numbering scheme (e.g. eqd-5 for rule 5 of Equity Derivatives)
- a Context evaluates from the document node to a resulting set of element nodes, the rule should then be applied separately to each member of the set
- a Context is qualified by an appropriate namespace unless it is in the default namespace (NB a section should define all applicable namespaces)
- context conditions qualify a context and therefore should appear after the context (this is important in the case of multiple contexts where different context conditions may apply)
- the current context is not carried through into a function. The function has no context other than its parameters
- a suitable set of valid and invalid test cases, which exercise the rule, will also need to be developed. NB each invalid test case must invalidate a single rule (and not any other rule)
- when a new rule is defined it should not invalidate any existing test cases
- there should be no redundant rules, e.g. A>B, B>C would make a rule of the form A>C redundant
- any term that is defined in XPath then that meaning is used for the term in the RuleDef. Any other term must be defined as a function
- literal values must be given a datatype. For example, the string "ISDA1999" refers to a value of xs:string
Rule layout:

An example rule:
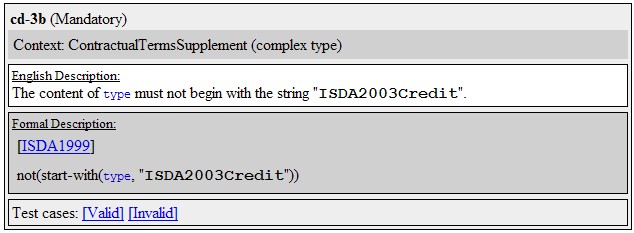
The above definition describes rule 3-b for credit derivatives. The context is type ContractualTermsSupplement, which is a complex type. The precondition ISDA1999 must evaluate to true. The rule body specifies that the node-element type must not begin with string “ISDA2003Credit” (finally, links to applicable valid and invalid test case documents.)
4.6.4 Defining New Terms as Functions
In the previous sections, the notion of expressing rules using stylized English was introduced; and the concomitant concept that a term should have the same meaning as the equivalent XPath expression. This section introduces functions as a mechanism to define repeatable tests that are applied independent of a context. Functions take node-element types as parameters and return a typed result.
Consider a test requiring that all currencies must be the same and that this applies for several different contexts. With reference to the schema it’s possible to identify that currency is applicable to all Money types and therefore define a function which accepts as a parameter a set of Money nodes:
| Function Name | same-currency |
| Description | the set of money elements must all contain the same currency |
| Parameter 1 | $money (fpml:Money) (min=2, max=*) |
| Result Type | xs:boolean |
| Test | Every $money/currency must be the same and every $money/currency/@currencyScheme must be the same |
This creates a new term same-currency which can be used as part of the definition of any validation rule.
NB The function does not inherit the context of where it is called from.
Each parameter name is prefixed with "$" to distinguish it from an XPath. Otherwise "money" might be either the parameter "$money" or the XPath "./money".
Each parameter has a minimum and maximum cardinality. This is given in the style of XML Schema. The cardinality must always be present. If the cardinality is not indicated, by default, the parameter must be provided once.
Each function must have a single result type.
There can be any number of parameters to a function.
4.6.4.1 How to use functions?
Once a new term (e.g., same-currency) is defined, it can be used as part of the definition of any validation rule (including conditions).
A reference to a new term must also include required parameters (within parenthesis and comma-delimited) as specified in the function definition. For example,
- same-currency((equityPremium/paymentAmount , notional))
- [exists(physicalSettlementTerms)] (example of Xpath function exists() used within a condition)
4.6.5 Formatting
Components of the validation rules may be differenciated by formatting as shown in the following table.
| Component | Formatting | Example |
| values | Courier New, 12pt, bold, black font | 100, ISDA2003Credit |
| xpath expressions and elements | Courier New, small 9pt, blue font | creditDefaultSwap/generalTerms/effectiveDate |
| functions | Times, 10pt, black font | exists(argument) |
Formatting is defined in stylesheet rules.css.
4.7.1 Implementations
For the purposes of precision, extensibility, and robustness to change the structure of the Validation Rules is profiled. The rules of the profile are:
- The context for a validation rule must always be a type. However, an element can be used for a context if there is no suitable type, because the context is a model group. If the context isn't a model group, then an element cannot be used."
- The paths from the context should be node names rather than types wherever posssible. For example "equityAmericanExercise" is preferred to "element(*, EquityAmericanExercise)".
- The context of the rule must be defined such that incorporates everything referred to in a rule. The rule must not use the ancestor or parent axis, or use them in cojunction with any other axis. For example "../../tradeHeader" is precluded.
4.7.2 Evaluation of Dates
The evaluation of dates in the validation rules is not trivial. The optionality of including time offsets in date datatypes makes comparisons between dates more difficult since sometimes the result is indeterminate as any ISO8601 date is +/- 18 hours of timezone, and +/- 24 hours of day.
The Validation Working Group recommends the use of the XPath 2.0 date/time comparison rules which defines a definitive true / false value even for indeterminate calculations.
The Validation Working Group recommends that time offsets appear on all date/time values used in FpML documents.
4.7.3 Contains
Many validation rules defined in FpML use the term 'contains'. FpML uses the definition of XPath 2's 'contains' (fn:contains) http://www.w3.org/TR/xpath-functions/#func-contains. This is significant for alphabets with accents, diaresis, etc.
Since the Validation Working Group was established after most product working groups, it still has a lot of work to complete before the rules span the whole product range, and indeed are reasonably complete for any particular product type. The latest set of validation rules is thus likely to change more frequently than the specification, and the process of rule publication has been decoupled from the specification.
The validation working group undergoes the following process in preparing its releases:
- Comments from previous publications are reviewed and logged as issues.
- The working group collaborates with selected experts from product working group to establish an initial set of rules, expressed in plain English.
- The rules are reviewed and extended, by performing a structured walk-through of the schema for the product type.
- The chairman of the Validation Working Group calls a freeze on the rule sets when a substantial set of new rules is available, or critical issues need to be urgently resolved.
- Test cases are written for each rule and ambiguities in the language addressed. This process usually leads to the elimination of some rules, and discovery of additional ones.
- The test cases must be validated by at least one reference implementation, and further ambiguities eliminated.
At the end of this process, a new URI is allocated for the revised rule set, and the rule set is announced and published as the new normative rule set on the FpML web site. We expect to publish the process to take on average three months for the foreseeable future.
The rule sets and test cases are the normative content published by the Validation Working Group. The reference implementations, see below, are informative and not part of the normative process. This normative characteristic has the implication that applications that construct FpML documents have to be designed so that their output meets the full set of validation constraints.
Applications that receive FpML for processing may want to check the validation rules to ensure that the data they are receiving represent a valid FpML document. Processing applications are not obliged to reject invalid messages. Instead, the implications of rule normativity are that the receiver gains the right to reject invalid messages. In other words, the sender has to either be prepared for rejection, or the rule set has to be tailored.
The validation working group is concerned that there may be legal implications due to this definition in situations where trades are executed between counter-parties. While we believe that the definition given above, providing a right for the receiver to reject trades and placing the burden on the sender, is the least controversial, we would like to obtain additional feedback on this issue before the publication of the final recommendation.