This section defines the FpML style for structuring XML schema. It defines the rules as they apply to the various components of an XML schema and shows how the basic elements of object oriented design would be mapped to XML types and elements.
The rules in this section have been based on the following XML schema recommendations:
-
XML Schema Part 1: Structures
-
XML Schema Part 2: Data Types
Additional information on XML schema and its usage can be found in this associated document:
-
XML Schema Part 0: Primer
2.1 Primitive Data Types
FpML uses a subset of the built-in data types as defined in the "XML Schema Part 2: Data Types" recommendation 2 May 2001 to define the type associated with simple scalar business data values (e.g. amounts, dates, names, etc.). The full set of built-in types available to an XML schema designer is defined in the following section of the standard.
If required, the size and other properties of these data types may be specified using the facets for them as described in the recommendation above. Examples are:
2.1.1 date & dateTime
The global nature of the finance industry means that under some circumstances it may be important to take into account time difference between the producer and consumer of FpML documents. For example a trade negotiated between parties in Sydney and San Francisco may appear to have two different trade dates when sent to matching service. Similar issues occur internally when trades negotiated in one geographic region are transmitted to another for processing and settlement.
The XML schema datatype for date and datetime values allow the inclusion of a time duration expressing the difference between local time and UTC (e.g. 2006-07-06+05:00). The time duration can be an hours and minutes value (e.g. hh:mm) up to plus or minus 14 hours from UTC.
The XML schema specification datatype section contains a description of how date and datetime values should be compared, taking into account their time duration offsets. These rules are implemented as part of XPath 2.0.
The AWG recommends that document creators be consistent and either generate a time duration offset on all date and dateTime values in an instance or none at all. Documents MUST not contain a mixture of values with and without time duration offsets. Processors of FpML documents MUST be capable of processing values with or without time duration offsets and SHOULD implement comparisons as defined in the XML schema datatypes specification.
FpML uses two main naming conventions throughout its definitions (sometimes with an additional suffix). In this document these conventions are referred to as 'lowerCamelCase' and 'UpperCamelCase'.
2.2.1 lowerCamelCase
An identifier conforming to lowerCamelCase convention MUST have:
-
First word or acronym in lower case.
-
All following words or acronyms with upper case first letter.
-
All other characters are lower case.
Numbers may appear between words or acronyms or at the end of the name. No other non-alphabetic characters may appear. For example:
-
href
-
tradeId
-
currencyScheme
-
currency1SideRate
-
fxAmericanTrigger
2.2.2 UpperCamelCase
An identifier conforming to the UpperCamelCase convention MUST have:
-
All words or acronyms with upper case first letter.
-
All other characters are lower case, including the remaining characters or acronyms.
Numbers may appear between words or acronyms or at the end of the name. No other non-alphabetic characters may appear. For example:
-
Interval
-
AmountSchedule
-
FxSpotRateSource
-
DateRelativeTo
2.2.3 Groups and Enumerations
- Groups are named with the suffix '.model'.
- Enumerations are named with the suffix 'Enum'.
2.2.4 Definitions and References
The following pattern distinguishes between Definitions and References:
- xyz - for the definition of the concept (i.e. trade)
- xyzId - for an identifier to the concept (i.e. tradeId)
- xyzReference - for an internal href reference to the concept (i.e. tradeReference)
2.2.5 Naming Anomalies
The FpML 4.0 grammar contains a few identifiers that do not confirm architecture specification naming conventions. Many of these identifiers existed within previous release of the grammar and changing them may affect operational systems or their ability to reprocess already archived documents.
This issue of when and how to bring these names into line with the conventions is being discussed by the FpML coordination committee. When corrections to identifier names take place they will be documented as part of the release documentation.
This section defines the design rules that FpML imposes of each feature of the XML schema language to ensure consistency of usage during the modelling process.
2.3.1 Qualification
All FpML defining schema MUST specify the qualification of their schema components such that:
-
All FpML defined elements and types MUST be qualified with an appropriate namespace declaration.
-
All FpML defined attributes MUST be unqualified.
The simplest way to achieve this is to set the qualification defaults on the schema root element as follows:
<xsd:schema xmlns:xsd = "http://www.w3.org/2001/XMLSchema" elementFormDefault = "qualified" attributeFormDefault = "unqualified"> ... </xsd:schema>
2.3.2 File Structure
In FpML each schema document when processed as the root schema must be valid XML Schema and have valid eCore reference attributes. This is not a rule enforced by the W3C XML Specification but it is required by FpML to avoid issues with tools.
2.3.2.1 Circular Dependency
A circular dependency arises when an included schema document includes a schema document that has been previously processed. A number of XML schema processing tools do not detect this situation and malfunction.
FpML schema documents MUST NOT include each other in a circular manner.
2.3.3 Attributes
FpML allows the use of attributes but restricts their usage to 'meta-data' such as the FpML version number, IDREF based intra-document links and URI definitions for externally referenced items.
No business (e.g. transaction, party or product, etc.) data is allowed to reside within an attribute. FpML favours the use of elements for such information because of their more powerful grammatical and modelling construction capabilities at the cost of larger document sizes.
When an attribute is defined within FpML its name MUST follow the convention of lowerCamelCase:
Attributes SHOULD be associated with either a XML schema built-in type or and FpML defined simple type to allow the parser to validate document instances.
FpML designers SHOULD avoid declaring attributes with global scope, instead they should be locally define within a containing element, type or attribute group.
2.3.4 Attribute Groups
Attributes groups MAY be used in FpML schemas to create a reusable set of attribute definitions and ensure consistency across a number of element or type definitions.
The name of an attribute group will never appear in an instance document, so its naming is not critical. However for consistency the AWG recommends that it use UpperCamelCase convention with the suffix '.atts' added. For example:
<xsd:attributeGroup name = "StandardAttributes.atts"> <xsd:attribute name = "version" use = "required"> <xsd:simpleType> <xsd:list> <xsd:simpleType> <xsd:restriction base = "xsd:normalizedString"> <xsd:enumeration value = "4-0"/> </xsd:restriction> </xsd:simpleType> </xsd:list> </xsd:simpleType> </xsd:attribute> </xsd:attributeGroup>
2.3.5 Elements
Elements define the vocabulary of tag names that can be used in an instance document to markup information. The XML schema language provides several ways in which elements may be used on their own or in conjunction with types to define a complex grammar.
The preferred style for FpML XML schema can be summarized as follows:
-
All elements other than the document root element (<FpML>) MUST follow the lowerCamelCase naming convention as described for attributes.
-
All elements MUST be associated with a globally defined type which defines their content (either a single value or a set of structured values).
-
All elements other than the document root element (<FpML>) and those which are used to create substitution groups MUST be defined locally within a containing complex type or model group.
The names of elements SHOULD be carefully selected to indicate clearly the business meaning of the data value or data structure. As XML structures information hierarchically the name of a contained element SHOULD NOT be prefixed with all or part of its parent element's name.
2.3.5.1 nillable
Element definitions within an FpML compliant schema may be marked as nillable to allow their content to be omitted from an instance document without breaking XML validation rules.
The use of nillable is only allowed within the schema to allow a document creator to omit element content which they can not reasonably be expected to provide at all times (e.g. to allow summary product definitions in pricing reports, etc.). Types and elements used to construct messages where full product definitions are required (e.g. confirmation, matching, etc.) are SHOULD NOT allow nillable element content.
2.3.5.2 Substitution Groups
An FpML schema MAY use substitution groups to create points of extension. In order for substitution to be possible the following standard schema conditions must apply:
-
The element to be substituted MUST be globally defined.
-
Substituting elements MUST be globally defined.
-
Substituting elements MUST be type compatible with the substituted element.
Currently FpML imposes the following extra condition:
-
The substituted element MUST be abstract to prevent its use in documents.
This final restriction may be removed in future FpML releases to allow type substitution to be used in preference to substitution groups. This change will allow greater use of XML Schema integrity features (e.g. keys and keyrefs) when used in conjunction with user extensions.
<product xsi:type="Swap"> ... Swap content model here </product>
2.3.5.3 Type Substitution
An instance document MAY choose to override the type of an element to substitute it with content defined by another compatible type (i.e. one defined by inheritance). Examples of this can be found in the messaging framework which uses type substitution on the <FpML> element to set the content model for the entire message.
The AWG believes that in most circumstances type substitution is a better approach than substitution groups and where possible should be used in preference (see the later section on extending FpML for examples).
2.3.6 Model Groups
Model groups allow the definition of a grammar fragment consisting of elements and their associated cardinalities. These grammar fragments may be referenced within other element and/or complex type definitions.
Like attribute groups, the name of an model group will never appear in an instance document, so its naming too is not critical. However for consistency the AWG recommends that it use UpperCamelCase convention with the suffix '.model' added. For example the following code defines a small model group consisting of two elements, <a> and <b>.
<xsd:group name = "Common.model"> <xsd:sequence> <xsd:element name = "a" type = "xsd:integer"/> <xsd:element name = "b" type = "xsd:decimal"/> </xsd:sequence> </xsd:group>
This model group can then be referenced from within the content model of another element or complex type as in the following example.
<xsd:complexType name = "TypeA"> <xsd:sequence> <xsd:group ref = "Common.model"/> </xsd:sequence> </xsd:complexType>
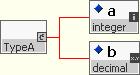
The content defined by such model groups can be combined with other model group references, global element references and/or local element definitions to create more complicated definitions such as the following example.
<xsd:complexType name = "TypeB"> <xsd:sequence> <xsd:group ref = "Common.model"/> <xsd:element name = "c" type = "xsd:string"/> </xsd:sequence> </xsd:complexType>
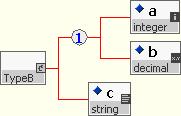
Using model groups in this manner with complex types creates structures that are similar to those generated by 'inheritance by extension' (described later), however the resulting types are not formally related and cannot be used in a type substitution (i.e. given the types in the example TypeB cannot substitute TypeA).
2.3.7 Simple Types
FpML allows the definition of simple types, especially where such definitions can be used to provide additional validation of scalar values. When a simple type is defined it MUST have an UpperCamelCase name.
Simple types may be defined as a restriction of an existing simple types (by means of a regular expression) or as a list of values (e.g. an enumeration). It should be noted that values accepted by the new type must also be accepted by all the parent types (e.g. it is not possible to remove the seconds component from a time, but you can ensure that it is always zero).
2.3.8 Complex Types
Complex types account for almost all of FpML's XML schema definitions. They are subject to the following conditions:
-
Complex types MUST be named according to the UpperCamelCase conventions.
-
A complex type MAY define a content model based on locally defined elements, globally define elements (for substitution groups) or through references to model groups.
-
A complex type MAY define attributes or reference an attribute group.
FpML allows complex types to be marked as abstract if they provide definition of features common to a number of over complex types that are derived by extension.
The use of inheritance by restriction is allowed between complex types as a way of limiting the content model of an existing type.
2.3.9 Content Models
XML schema allows the content model for a complex type to be defined in a number of ways. This section describes the preferred options within an FpML schema.
2.3.9.1 Sequential
The most common way to specify the structure of some information is as a sequence of elements, each with a given cardinality (e.g. zero, one, unbounded or a specific number). To be valid an instance document must match the order of the elements as defined in the content model (allowing for cardinality).
Sequential defined content MAY contain choice groups whether alternative element orders are possible.
2.3.9.2 Choice Groups
Choice groups define a series of alternative element sequences that may appear with the content.
Care must be taken when defining choice groups to ensure that the grammar remains 'deterministic' (i.e. given a set of alternative rules the parser must be able to select the correct grammatical rule to apply based on the current token and those it has seen previously). For example consider the grammar for a type consisting of two elements, <a> and <b>, which may appear individually or together.
The most obvious grammar is one that simply lists the three possible outcomes that are allowed (e.g. <a>, <b>, and <a><b>) as shown in this diagram.
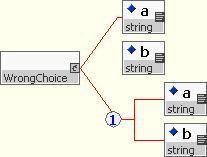
This grammar is non-deterministic because the two of the rules start with the same element pattern (e.g. <a>) and the parser could select the wrong one. The correct way to express this simple choice is to combine the <a> and <a><b> options into a single rule in which element <b> is optional. Each of the choices now starts with a different element making the correct rule obvious to the parser.
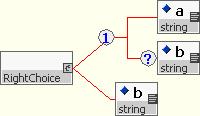
2.3.9.3 Ordering within Repetitions
Many of the elements that comprise of the FpML schema are allowed to repeat (i.e. their 'maxOccurs' attribute has a value greater than one or is 'unbound'). In almost all cases the order in which the repeating structures are generated within the document has no impact on the overall business interpretation of the data being described.
There are a small number of exceptions to this where the business data has no naturally occurring values that can be used to imply an ordering (e.g. repeating postal address lines) and the order of appearance must be treated as significant.
Processing applications MUST NOT assume that the order of data in a document is significant if it contains sufficient business values to allow an ordering to derived during processing. For example the sequence of 'legs' within a product, business center codes in a list, cashflows, Bermudian exercise dates, etc. SHOULD NOT be assumed to be any particular order (e.g. first to last, lexical, etc.).
2.3.9.4 Unordered Content
XML schema provides a facility for defining a content model in which the contained elements may appear in any order within the instance document. This style of definition is not relevant to FpML documents and SHOULD NOT be used in FpML define XML schemata.
2.3.9.5 Mixed Content
FpML DOES NOT allow the used of mixed content within elements. An FpML element MUST contain either a single data value (e.g. integer, date, enumerated value, etc.) or a series of sub-elements described by a selection of sequences and/or choice groups.
2.3.9.6 Validation
The way in which the content model for a complex type or model group is designed directly affects the amount of validation that can be performed during XML parsing and the amount that will have to be performed subsequently by program code. For example, it is often the case that the elements comprising the definition of a complex business object are related such that the presence of one implies the presence or absence of others.
A simple approach to modelling such business objects is to consider only the cardinality of each element. This leads to the creation of types containing a single sequence of mandatory and optional elements. Whilst such types will accept all valid element sequences they also accept invalid element combinations because the grammar does not express any inter-element relationships.
Using a combination of sequences and choices the XML grammar for a complex business object can be constrained to make it reject instances using invalid element combinations at the cost of a more complex content definition. Which such definitions may not be able to rule out every invalid case they significantly reduce the number of invalid combinations that must be checked through the use of programmed validation rules.
The AWG believes that in the interest of consistency of validation and interpretation between FpML processors the use of validating content definitions is preferred.
2.3.10 Boolean Values
A boolean value is one that can have only two possible states. The simplicity of these values means that there are several possible ways to model them in XML schema, each having its own set of pros and cons. Further complexity is often introduced by the requirement to have the value itself be optional, so that it can be excluded from product variants or a message structure where it is not required.
Using the features of schema and the conventions established for FpML there are four techniques that could be applied to the modelling of booleans, namely:
-
The presence or absence of an optional empty element.
<isCashSettled/>
-
An element defined using the XML schema defined boolean type and allowed to contain one of the values 'true', 'false', '1' or '0'.
<isCashSettled>false</isCashSettled>
-
An element defined using a simple type representing an enumeration of two possible values.
<settlementMethod>Cash</settlementMethod> <settlementMethod>Physical</settlementMethod>
-
An element defined using a scheme referencing type where the scheme itself supports only two valid code values.
<settlementMethod settlementMethodScheme="http//...">Cash</settlementMethod> <settlementMethod settlementMethodScheme="http//...">Physical</settlementMethod>
If the values 'true' and 'false' adequately express the semantics of the data value then the preferred FpML approach is the second, that is, boolean values MUST BE modelled using the XML schema type boolean. For example:
.. <principalExchanges> <initialExchange>true</initialExchange> <finalExchange>true</finalExchange> <intermediateExchange>false</intermediateExchange> </principalExchanges> ...
This approach is consistent with the modelling of other value types and allows values to be absent if not required.
There are a few cases in the FpML schema where the existence of an empty element has been used in the model. These MAY BE deprecated and replaced in future releases of FpML.
In many cases the use of an enumeration may provide clearer business explanation of the two states than a simple 'true' or 'false'. This method SHOULD also be used if there is any possibility of there being more that two states at some point in the future. For example if we wanted to add 'Chattel' an acceptable form of settlement at a later time then using an enumeration would allow the new state to be introduced without breaking backwards compatibility.
Scheme based enumerations usually have a large domain of possible values which change frequently. Whilst technically possible, using a scheme reference to express a boolean value is not an effective solution.
2.3.11 Scheme Values
The XML schema type 'token' MUST be used as the datatype for elements containing scheme code values. In addition the 'maxLength' facet MUST be set so that the code is limited to 255 characters. This is a new constraint not imposed in FpML releases prior to 4.5 and is intended to assist with mapping XML to persistent storage, such as relational databases.
In practice code values SHOULD NEVER need to be as long as 255 characters and the AWG recommends that designers never create codes longer that 127 characters. FpML's own modelling working groups WILL NEVER define a code longer than 63 characters.
2.3.12 Annotation
Designers of FpML XML schemata MUST embed documentation within their schema components to enable the production of documentation automatically from the schema source. All global types and elements MUST have a definition. XML schema allows multiple annotations for each component differentiated by the 'xml:lang' attribute and designers MAY provide multi-lingual text. Documentation MUST always be included within an xsd:annotation. 'Floating' documentation (or comments) is not allowed in the FpML schemata.
<xsd:element name="valuationTime" type="BusinessCenterTime"> <xsd:annotation> <xsd:documentation xml:lang="de">Genaue Tageszeit, zu der die Bewertungsstelle den Basiswert bewertet. </xsd:documentation> <xsd:documentation xml:lang="en">The specific time of day at which the calculation agent values the underlying. </xsd:documentation> </xsd:annotation> </xsd:element>
The FpML organisation WILL maintain a fully annotated XML schema, at each release, as its normative definition of the FpML grammar. The FpML organisation MAY in addition publish non-annotated normative copies of the schema for time critical processing applications (to eliminate the risk that users may inadvertently change the schema whilst removing the annotation themselves).
2.3.13 Deprecated Structures
2.3.13.1 Definition
Any feature that appears in the resultant XML document or process instance may be deprecated - a node, code value, URI, correlation, etc.
A deprecated feature of FpML is one that should not be used. Deprecation is indicated to discourage usage. A feature is marked as deprecated temporarily to provide backwards compatibility.
A deprecated feature will almost always be removed in the next major version, though retention can be justified.
For full backwards compatibility, it is recommended to stay on the same version of the schema the implementer wishes to remain compatible with.
2.3.13.2 Flag
FpML defines a deprecated flag as an attribute to the FpML Schema to point at deprecated features that will be removed in the next major release. fpml-annotation:deprecated="true" is used to mark something as deprecated. In addition, a fpml-annotation:deprecatedReason attribute contains the rationale of the deprecation. These attributes are defined within a separate namespace called http://www.fpml.org/annotation.
<xsd:element name="contractualSupplement" type="ContractualSupplement" minOccurs="0"
maxOccurs="unbounded" fpml-annotation:deprecated="true"
fpml-annotation:deprecatedReason="The contractualTermsSupplement includes the publication date,
which was not present in the contractualSupplement">
<xsd:annotation>
<xsd:documentation xml:lang="en">DEPRECATED - This element will be removed in the next major
version of FpML. The element contractualTermsSupplement should be used instead. Definition: A
contractual supplement (such as those published by ISDA) that will apply to the trade</xsd:documentation>
</xsd:annotation>
</xsd:element>
Broadly speaking, FpML has always used an object-oriented approach for data modelling, however the resulting model has always been expressed directly in XML. Originally its designers used object oriented techniques to design and mapped the result structures into the with the resulting model as either an XML schema or DTD (for releases up to FpML 3.0).
2.4.1 Types
In object-oriented design, a class defines a common set of data attributes and functionality that will be present in any instance of the type. Because XML is not procedural, only the data members of a class are mapped to XML types and elements.
For example, the FpML type used to represent monetary amounts could be represented (using UML) as class with the following structure.
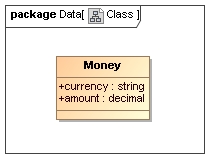
The simplest mapping for such types into XML schema structures is through the use of 'complex types'. Such definitions allow a rich content model to be associated with the class and also the construction of further types through the use of inheritance. Both features are described later. The corresponding XML schema definition for this simple class is shown below.
<xsd:complexType name = "Money"> <xsd:sequence> <xsd:element name="currency" type="xsd:token"/> <xsd:element name="amount" type="xsd:decimal"/> </xsd:sequence> </xsd:complexType>
XML schema supports the embedding of textual annotation within schema definitions to describe the role of each definition. This feature should be used to document each of the types and its constituent members, although for brevity such annotations have been omitted from this document.
2.4.1.1 Complex Content
Frequently the members that comprise a class are related in someway. Often the presence of one may imply the presence or absence of one or more other members. Such relationships can be captured in the XML schema group the use of choice groups.
The existence of a overly complex content model may suggest that a class is poorly designed and would be better factored into either a number of alternative sub-types or should be constructed through aggregation. Sometimes the design may be completely justified as is.
The AWG suggests that designers who find themselves with such models examine the possibility of using inheritance and/or aggregation to see if it would yield a better model. Complex content should only be used if the alternatives are unacceptable.
2.4.2 Inheritance
Inheritance allows for the construction of new types from existing ones. XML schema supports two styles of inheritance, by extension and by restriction, of which the former is the more familiar to object oriented designers and programmers.
2.4.2.1 By Extension
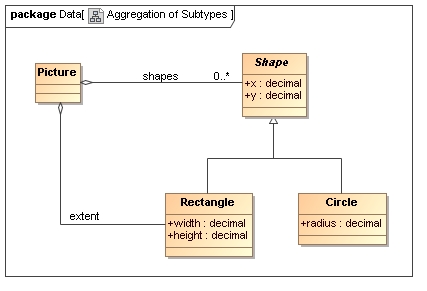
XML Schema supports a single inheritance pattern between complex types by extension. Usually the base type represents a 'generalized' structure that becomes more 'specialized' in the derived type. For example in a simple type hierarchy for graphics a base Shape type might hold the location of a shape on the drawing surface (e.g. the top left corner) whilst derived types provide the information required to draw specific types of shape (e.g. side length of a square, radius of a circle, etc.).
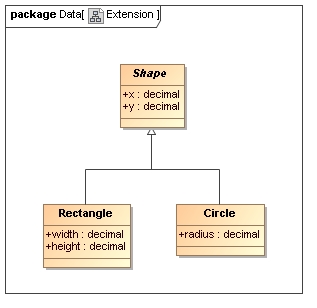
Under this style of inheritance the content model inherited from the base type by the new derived type cannot be modified. Any data member defined in a base types will be present in all the derived types with the same cardinality (e.g. optional, one, multiple, etc.).
It's important to note that the use of extension in FpML is restricted to genuine cases of extension by inheritance, rather than a mechanism for grabbing a set of common properties.
2.4.2.2 By Restriction
Inheritance by restriction is an alternative way of defining a specialization where instead of adding additional information during the derivation we take it away. The base type in a restriction represents the most general form of a type, its content typically being the superset of all the data present in all of its derived types. Each sub-type selects a sub-set of the available data members and may select a cardinality for the member which is within the bounds of the original definition (e.g. a non-repeating optional element may be omitted in the derive type but cannot be made repeating).
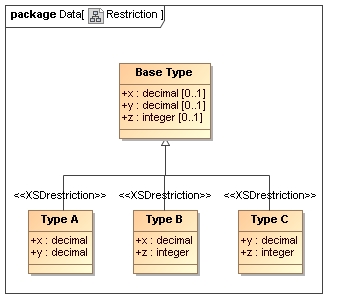
Inheritance by restriction is useful where each of the sub-type appears to be a variation sharing many similar properties to its siblings.
Where as inheritance by extension has a simple and direct mapping into object orient programming class structures that allow many usage errors to be detected during compilation. If restriction is present then many of checks must be performed at runtime as instances are accessed.
FpML no longer recommends the use of inheritance by restriction (for complex types) because of implementation issues and all instances of it where removed in release 4.2.
2.4.3 Abstract Types
An abstract type is a type that may not be instantiated within a document. Such types are frequently used to represent the properties common to a number of related sub-types, such as financial products.
Abstract types often indicate points in the grammar where users may wish to create their own extensions.
2.4.4 Arrays (Sequences)
There are two basic approaches for the handling of arrays or sequences of repeating data in XML, namely:
-
Simply repeat the required element as many times as necessary between its sibling element. This creates the simplest XML definitions and documents. For example:
<fullName> <firstName>Liam</firstName> <initial>A</initial> <initial>C</initial> <familyName>Jacobs</familyName> </fullName>
-
Define a container to hold the repeating element and use the container in the parent element. This assists in programming message construction and parsing.
<fullName> <firstName>Liam</firstName> <initials> <initial>A</initial> <initial>C</initial> <initials> <familyName>Jacobs</familyName> </fullName>
Unfortunately most XML book authors use both styles inconsistently in their texts and hence are unreliable references of what constitutes good XML style so the FpML 1.0 Architecture specification choose the simpler representation as the standard for FpML documents. Hence the mapping that would be applied in the case of the following model is simply a repetition of the element <detail> inside the containing <master> between any sibling elements
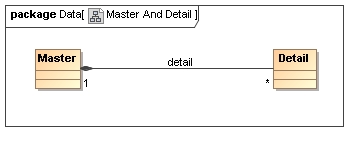
It has been noted that some other standards have chosen to go with the container approach, however in most cases the container not only provides grouping but also carries additional attributes or elements describing some property of the collection as a whole (e.g. in FixML an OrderList has a ListNoOrders attribute, etc.). If such information where required for a container in FpML then it would be represented as follows, although to date no FpML working group has found the need to do this.
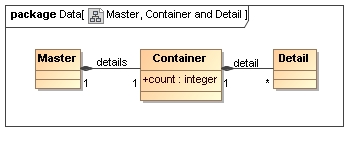
Such a model would result in documents with the following content:
<master> ... <details> <count>2</count> <detail>...</detail> <detail>...</detail> </details> </master>
2.4.5 Association
An association represents a relationship between two independent objects. The relationship normally has a 'role' that represents the purpose to which the associate object is put.
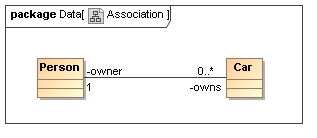
One type may have many associations to same target type provided that the purpose of each association can be determined. A simple way to do this is to use the associations 'role' name to name the element use to record it in an XML document.
2.4.6 Aggregation
Like association, aggregation is a relationship between two objects. However, unlike association, the aggregated object does not have an independent existence.
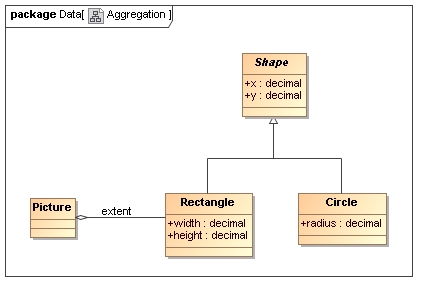
2.4.7 Aggregation of Sub-Types
Aggregation of sub-types is a special case of aggregation where the aggregated data consists of instances of types which all have a common base type. In the case of our simple graphical example we can imagine that a picture is an aggregation of many shapes, where each shape is an instance of a type derived from the Shape type.